Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to use OCR to extract text from PDF in ASP.NET, C#, C++, VB.NET and VBScript using ByteScout PDF Extractor SDK
When developing data mining applications, scanned documents are a hurdle for developers. Bytescout PDF ExtractorSDK provides an easy way to extract data from scanned PDF documents. In this article, we’ll see how to extract text from scanned documents using the ByteScout PDF Extractor SDK with different languages such as C# (ASP.Net), C++, VB, and VB6 as well as using the features of ByteScout OCR language.
In order to execute programs mentioned in this article in your machine, you’ll need to install Bytescout SDK. You can get your free trial from this URL.
These code samples will demonstrate how to use OCR(Optical Character Recognition) to extract text from a PDF document in ASP.NET, C#, C++, VB.NET, and VBScript using ByteScout PDF Extractor SDK.
How to use OCR to extract text from PDF in ASP.NET
using System;
using Bytescout.PDFExtractor;
// To compile the example copy missing .traineddata files from REDISTRIBUTABLE folder to "tessdata" project folder.
// or download from http://code.google.com/p/tesseract-ocr/downloads/list
// Make sure "Copy to Output Directory" property of each added language file is set to "Copy always".
// Note: Do not rename the "tessdata" folder - its name is hardcoded in OCR engine.
namespace WebApplication1
{
public partial class Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
String inputFile = Server.MapPath("sample_ocr.pdf");
// Set the location of
String ocrLanguageDataFolder = Server.MapPath(@"tessdata");
using (TextExtractor extractor = new TextExtractor())
{
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// setup OCR
extractor.OCRMode = OCRMode.Auto;
extractor.OCRLanguageDataFolder = ocrLanguageDataFolder;
extractor.OCRLanguage = "eng";
extractor.OCRResolution = 300;
extractor.LoadDocumentFromFile(inputFile);
// Write extracted text to output stream
Response.Clear();
Response.ContentType = "text/html";
Response.Write(extractor.GetText());
Response.End();
}
}
}
}
How to use OCR to extract text from PDF in C#
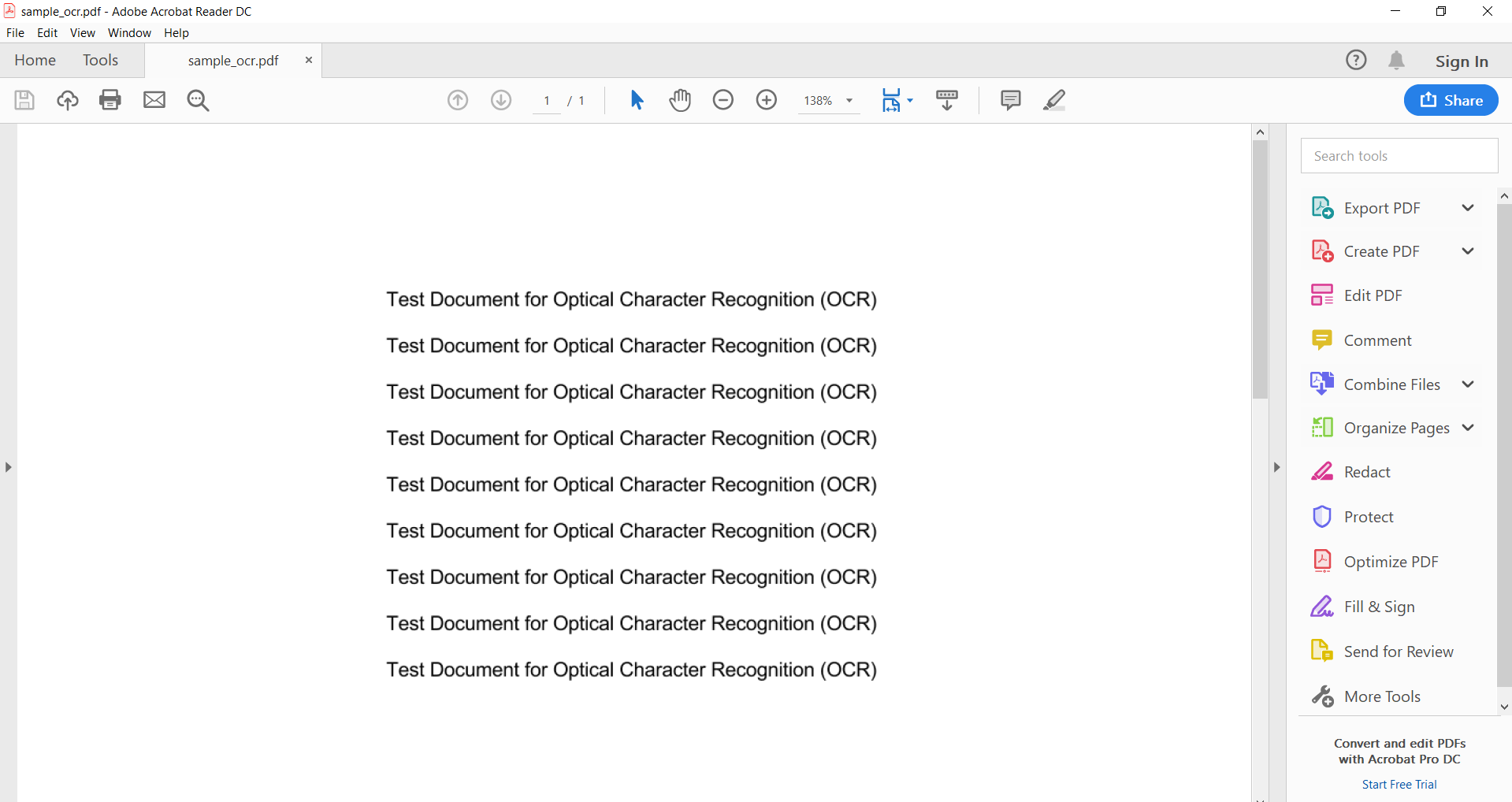
Here you will see how to proceed with OCR on PDF C#. We’ll use input PDF like on the screenshot:
First of all, let’s create a console application and add a reference to “Bytescout PDF Extractor” assembly.
Then follow the steps to add SDK functionalities in your application.
Create a text extractor instance.
Load Sample PDF file on which you are going to process.
Enable OCR extractor mode at auto.
Set the location of the “testdata” folder containing language data files.
Set OCR Language.
Set PDF document rendering resolution.
Save extracted text to file.
Open output file in default associated application.
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.TextExtractor instance
TextExtractor extractor = new TextExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile("sample_ocr.pdf");
// Enable Optical Character Recognition (OCR)
// in .Auto mode (SDK automatically checks if needs to use OCR or not)
extractor.OCRMode = OCRMode.Auto;
// Set the location of "tessdata" folder containing language data files
extractor.OCRLanguageDataFolder = @"c:\Program Files\Bytescout PDF Extractor SDK\Redistributable\net2.00\tessdata\";
// Set OCR language
extractor.OCRLanguage = "eng"; // "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in /tessdata
// Set PDF document rendering resolution
extractor.OCRResolution = 300;
// Save extracted text to file
extractor.SaveTextToFile("output.txt");
// Open output file in default associated application
System.Diagnostics.Process.Start("output.txt");
}
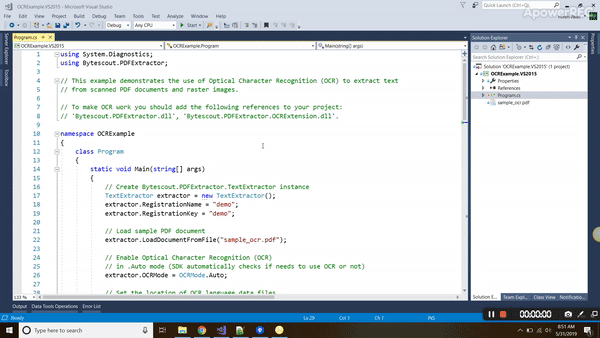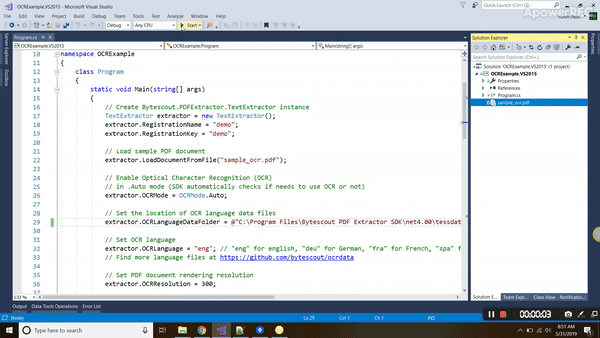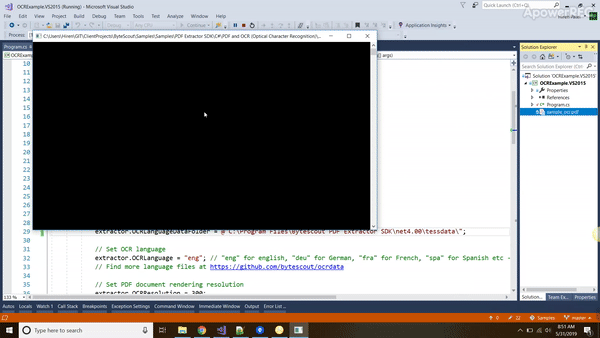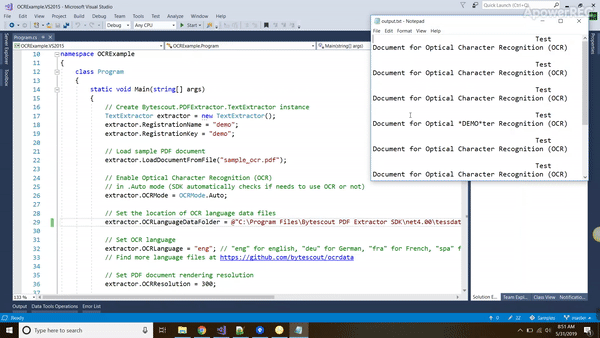
And here’s the output.
Though the code is pretty explanative, Let’s analyze it step by step.
1. Create TextExtractor Reference
// Create Bytescout.PDFExtractor.TextExtractor instance TextExtractor extractor = new TextExtractor(); extractor.RegistrationName = "demo"; extractor.RegistrationKey = "demo";
As we’re developing a program to simply extract all text from PDF document, We’ll be using TextExtractor class from Bytescout.PDFExtractor assembly. After creating an instance, we’ll be assigning registration key and name. In this case, it is using demo keys, but you can certainly replace it with actual keys which one will retrieve upon purchasing Bytescout SDKs.
2. Load input document.
// Load sample PDF document extractor.LoadDocumentFromFile("sample_ocr.pdf");
Here, we’re loading the document from the physical path, but one can certainly use memory stream by using LoadDocumentFromStream method.
3. Enabling OCR and setting OCR related properties based on the requirement
// Enable Optical Character Recognition (OCR) // in .Auto mode (SDK automatically checks if needs to use OCR or not) extractor.OCRMode = OCRMode.Auto;
// Set the location of "tessdata" folder containing language data files extractor.OCRLanguageDataFolder = @"c:\Program Files\Bytescout PDF Extractor SDK\Redistributable\net2.00\tessdata\"; // Set OCR language extractor.OCRLanguage = "eng"; // "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in /tessdata
// Set PDF document rendering resolution extractor.OCRResolution = 300;
We are enabling OCR mode for TextExtractor instance, and setting it to auto mode, so that assembly will automatically detect whether OCR is required and if so it’ll apply OCR. Then we have given the path for OCR language data folder. This path contains all language data required by OCR to parse image to text.
Next is setting the language of the document, we are using language code for English (“eng”) here. After that we are setting OCR resolution, to indicate how much processing required to parse image.
There are many OCR related properties available which gave us fine-grained control over image parsing, especially when the image is of low quality. Following examples are some of them.
// Save extracted text to file extractor.SaveTextToFile("output.txt");
After all properties are set, we are ready for getting output. Here we’re using “SaveTextToFile” method, which, as its name suggests saves output to physical file. We can also use SaveTextToStream method if we need to store output file to memory stream.
Just like we have done for C# console applications, followings are the programs in different languages/environments.
How to use OCR to extract text from PDF in C++
#include "stdafx.h"
#include "comip.h"
#import "c:\\Program Files\\Bytescout PDF Extractor SDK\\net4.00\\Bytescout.PDFExtractor.tlb" raw_interfaces_only
using namespace Bytescout_PDFExtractor;
int _tmain(int argc, _TCHAR* argv[])
{
// Initialize COM.
HRESULT hr = CoInitializeEx(NULL, COINIT_APARTMENTTHREADED);
// Create the interface pointer.
_TextExtractorPtr pITextExtractor(__uuidof(TextExtractor));
// Set the registration name and key
// Note: You should use _bstr_t or BSTR to pass string to the library because of COM requirements
_bstr_t bstrRegName(L"DEMO");
pITextExtractor->put_RegistrationName(bstrRegName);
_bstr_t bstrRegKey(L"DEMO");
pITextExtractor->put_RegistrationKey(bstrRegKey);
// Load sample PDF document
_bstr_t bstrPath(L"..\\..\\sample_ocr.pdf");
pITextExtractor->LoadDocumentFromFile(bstrPath);
// Enable Optical Character Recognition (OCR)
// in .Auto mode (SDK automatically checks if needs to use OCR or not)
pITextExtractor->put_OCRMode(OCRMode_Auto);
// Set the location of "tessdata" folder containing language data files
_bstr_t bstrOCRLangDataPath(L"c:\\Program Files\\Bytescout PDF Extractor SDK\\net4.00\\tessdata");
pITextExtractor->put_OCRLanguageDataFolder(bstrOCRLangDataPath);
// Set OCR language
_bstr_t bstrOCRLanguage(L"eng");
pITextExtractor->put_OCRLanguage(bstrOCRLanguage);
// Set PDF document rendering resolution
pITextExtractor->put_OCRResolution(300);
// Save extracted text to file
_bstr_t bstrOutputFile(L"output.txt");
pITextExtractor->SaveTextToFile(bstrOutputFile);
pITextExtractor->Release();
CoUninitialize();
return 0;
}
How to use OCR to extract text from PDF in Visual Basic .NET
Imports Bytescout.PDFExtractor
' To make OCR work you should add to your project references to Bytescout.PDFExtractor.dll and Bytescout.PDFExtractor.OCRExtension.dll
Class Program
Friend Shared Sub Main(args As String())
' Create Bytescout.PDFExtractor.TextExtractor instance
Dim extractor As New TextExtractor()
extractor.RegistrationName = "demo"
extractor.RegistrationKey = "demo"
' Load sample PDF document
extractor.LoadDocumentFromFile("sample_ocr.pdf")
' Enable Optical Character Recognition (OCR)
' in .Auto mode (SDK automatically checks if needs to use OCR or not)
extractor.OCRMode = OCRMode.Auto
' Set the location of "tessdata" folder containing language data files
extractor.OCRLanguageDataFolder = "c:\Program Files\Bytescout PDF Extractor SDK\Redistributable\net2.00\tessdata\"
' Set OCR language
extractor.OCRLanguage = "eng" ' "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in /tessdata
' Set PDF document rendering resolution
extractor.OCRResolution = 300
' Save extracted text to file
extractor.SaveTextToFile("output.txt")
' Open output file in default associated application
System.Diagnostics.Process.Start("output.txt")
End Sub
End Class
How to use OCR to extract text from PDF in VBScript (Visual Basic 6)
' Create TextExtractor object
Set extractor = CreateObject("Bytescout.PDFExtractor.TextExtractor")
extractor.RegistrationName = "demo"
extractor.RegistrationKey = "demo"
' Load sample PDF document
extractor.LoadDocumentFromFile("..\..\sample_ocr.pdf")
' Enable Optical Character Recognition (OCR)
extractor.OCRMode = 1 ' OCRMode.Auto = 1
' Set the location of "tessdata" folder containing language data files
extractor.OCRLanguageDataFolder = "c:\Program Files\Bytescout BarCode SDK\Redistributable\tessdata"
' Set OCR language
' "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in "tessdata" folder.
extractor.OCRLanguage = "eng"
' Set PDF document rendering resolution
extractor.OCRResolution = 300
' Save extracted text to file
extractor.SaveTextToFile("output.txt")
MsgBox "Text was extracted to output.txt"
Set extractor = Nothing