Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
Extract data from PDF coordinates in C# with PDF Extractor SDK
Extracting data from a particular region of PDF seems a small task when doing it manually, but automating this process has huge time and cost-saving benefits.
One of the main features of the ByteScout PDF Extractor SDK is to convert PDF to Text data. We can either convert the whole PDF file to a text file or a selected number of pages to text output. This can be also further refined to extract certain areas of input PDF and convert to a text file. In this article, we’ll be observing how efficient the ByteScout PDF Extractor SDK is to extract text data from a certain region of PDF file.
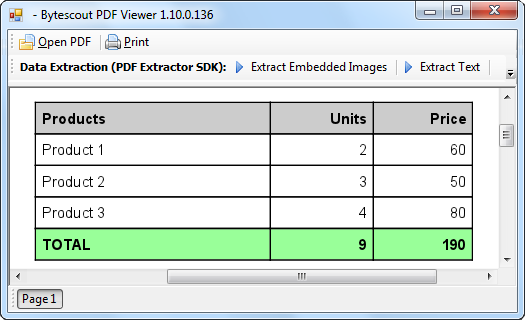
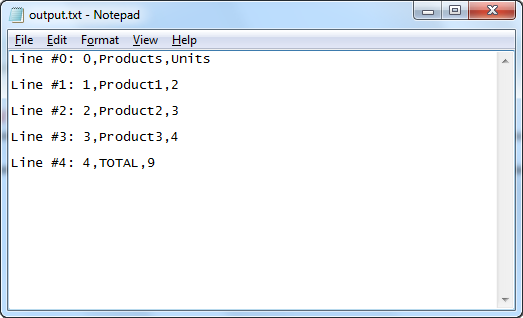
In these screenshots, you can see the input PDF table and output TXT file with data extracted from the given coordinates.
Input PDF File
Output Text File
Program Source Code in C#
The C# sample below shows how to extract data from PDF files based on coordinates into a TXT file using PDF Extractor SDK.
using System;
using System.IO;
using System.Text;
using Bytescout.PDFExtractor;
using System.Drawing;
using System.Diagnostics;
namespace Example
{
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.TextExtractor instance
TextExtractor extractor = new TextExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile("sample3.pdf");
// Table dimensions (measured in points by hand using the original 100% scaled PDF document)
const int tableX = 207;
const int tableY = 110;
const int rowHeight = 24;
const int col1width = 177;
const int col2width = 76;
const int col3width = 76;
StringBuilder stringBuilder = new StringBuilder();
// Parse text from table cells
for (int row = 0; row < 5; row++)
{
extractor.SetExtractionArea(Rectangle.FromLTRB(tableX, tableY + row * rowHeight, tableX + col1width, tableY + row * rowHeight + rowHeight));
string cell1 = extractor.GetTextFromPage(0).Trim();
extractor.SetExtractionArea(Rectangle.FromLTRB(tableX+ col1width, tableY + row * rowHeight, tableX + col1width + col2width, tableY + row * rowHeight + rowHeight));
string cell2 = extractor.GetTextFromPage(0).Trim();
extractor.SetExtractionArea(Rectangle.FromLTRB(tableX + col1width + col2width, tableY + row * rowHeight, tableX + col1width + col2width + col3width, tableY + row * rowHeight + rowHeight));
string cell3 = extractor.GetTextFromPage(0).Trim();
Console.WriteLine("Line #{0}: {1}, {2}, {3}", row, cell1, cell2, cell3);
stringBuilder.AppendFormat("Line #{0}: {0},{1},{2}rnrn", row, cell1, cell2, cell3);
}
// Save text to file
File.WriteAllText("output.txt", stringBuilder.ToString());
Console.WriteLine();
Console.WriteLine("Data has been extracted to 'output.txt' file.");
Console.WriteLine();
Console.WriteLine("Press any key to continue to open OUTPUT.TXT in Notepad...");
Console.ReadKey();
Process.Start("output.txt");
}
}
}
Though the program is pretty self-explaining, let’s review its main code snippets.
In this code snippet, we’re creating an instance of ‘TextExtractor‘ class which comes under “Bytescout.PDFExtractor” assembly and namespace. We’re also initializing properties for registration name and key. In this sample, we’re providing demo keys that cause text watermark in output. When in production we should use the original key and name field values received at the time of purchasing SDK so that it’ll have clean and faster output.
Providing Input file
// Load sample PDF document
extractor.LoadDocumentFromFile("sample3.pdf");
In this snippet, we’re using the method ‘LoadDocumentFromFile‘ to load input PDF file from file system either from local drive or networked drive. We often have scenarios when input files are not physically present but available from the output of other operations. In these cases, we can use the method ‘LoadDocumentFromStream‘, which allows loading input PDF in form of a stream.
Set extraction area and read text from it
This is an important code snippet where the real action is happening.
As the name suggests method ‘SetExtractionArea‘ sets the area from which data needs to be extracted. This method requires data in form of a rectangle (Sytem.Drawing.Rectangle) object.
We’re creating an input Rectangle object by using the method “Rectangle.FromLTRB“. This method “FromLTRB” is an acronym for “From Left Top Right and Bottom” and expects left, top, right, and bottom coordinates in pixel.
The next line of code-snippet is to get text data from the set extraction region. Here we’re using the method “GetTextFromPage” by providing a zero-based page index to it.
There are also other method variation available like “GetText“, “SavePageTextToFile“, “SavePageTextToStream” with multiple method overloading versions. Please analyze SDK methods in documentation for more information.
That’s all guys! Thank you for reading!
To get more from this article, I suggest you try this sample on your machine. You’ll require to install ByteScout SDKs on your machine which you can get from the following links.