PDF to JSON in C# and ByteScout PDF Extractor SDK
How to Use ByteScout PDF Extractor SDK for PDF to JSON in C#
ByteScout tutorials explain the material for programmers who use C#. ByteScout PDF Extractor SDK helps with PDF to JSON in C#. ByteScout PDF Extractor SDK is the Software Development Kit (SDK) that is designed to help developers with data extraction from unstructured documents like PDF, TIFF, scans, images, and scanned and electronic forms. The library is powered by OCR, computer vision, and AI to provide unique functionality like table detection, automatic table structure extraction, data restoration, data restructuring, and reconstruction. Supports PDF, TIFF, PNG, JPG images as input and can output CSV, XML, and JSON formatted data. Includes a full set of utilities like PDF splitter, PDF merger, and searchable PDF maker.
The SDK samples like this one below explain how to quickly make your application do PDF to JSON in C# with the help of ByteScout PDF Extractor SDK. This C# sample code should be copied and pasted into your application’s code editor. Then just compile and run it to see how it works. Enjoy writing a code with ready-to-use sample C# codes to implement PDF to JSON using ByteScout PDF Extractor SDK.
ByteScout PDF Extractor SDK free trial version is available for download from our website. Free trial also includes programming tutorials along with source code samples.
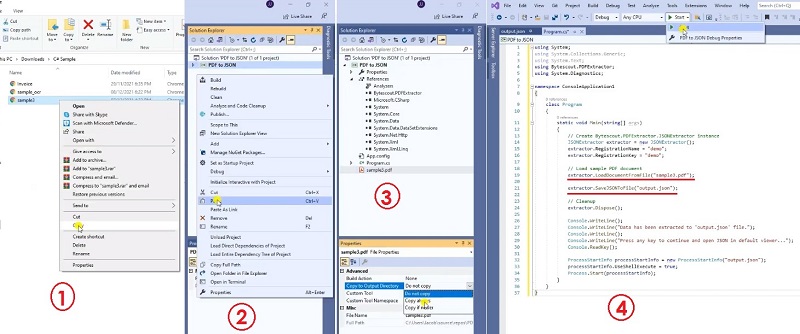
In this tutorial, we will extract data from PDF to JSON output. Let’s copy the sample code and paste it into the Visual Studio editor. I added the sample code link in the description box below. To extract the PDF files, we will use the ByteScout PDF Extractor SDK. You can add a reference to the PDF Extractor SDK DLL and the Solution Explorer. Right-click on reference and select add reference. Look up the PDF Extractor SDK and add. Then add your registration name and registration key and their related properties accordingly.
You can get your license details in the ByteScout dashboard. We will add our sample file in the solution explorer and set the copy to the output directory to ‘copy always’. Then load the sample file in the loaded document from the file property. Our output will be saved to a JSON file. Now let’s run the program.
Our data has been extracted to JSON output. Let’s click the folder to see the output.