Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
The source code sample below will help you merge multiple PDF files in C#. You can also find a video guide at the end of this article.
using System.Diagnostics;
using Bytescout.PDFExtractor;
namespace MergeDocuments
{
class Program
{
static void Main(string[] args)
{
string[] inputFiles = new string[] {"sample1.pdf", "sample2.pdf", "sample3.pdf"};
using (DocumentMerger merger = new DocumentMerger("demo", "demo"))
{
merger.Merge(inputFiles, "result.pdf");
}
Process.Start("result.pdf");
}
}
}
How to Merge Multiple PDF Documents in C++
Check out the following code snippet to learn how you can merge multiple PDF files in C++ programming language.
#include "stdafx.h"
#include "comip.h"
// you may also refer to the tlb from \net4.00\ folder
// you may also want to include the tlb file into the project so you could compile it and use intellisense for it
#import "c:\\Program Files\\Bytescout PDF Extractor SDK\\net2.00\\Bytescout.PDFExtractor.tlb" raw_interfaces_only
using namespace Bytescout_PDFExtractor;
int _tmain(int argc, _TCHAR* argv[])
{
// Initialize COM.
HRESULT hr = CoInitializeEx(NULL, COINIT_APARTMENTTHREADED);
// Create the interface pointer.
_DocumentSplitterPtr pIDocumentSplitter(__uuidof(DocumentSplitter));
// Set the registration name and key
// Note: You should use _bstr_t or BSTR to pass string to the library because of COM requirements
_bstr_t bstrRegName(L"DEMO");
pIDocumentSplitter->put_RegistrationName(bstrRegName);
_bstr_t bstrRegKey(L"DEMO");
pIDocumentSplitter->put_RegistrationKey(bstrRegKey);
// you may enable optimization for extracted pages from documents
// pIDocumentSplitter->put_OptimizeSplittedDocuments = true;
// Load sample PDF document
HRESULT sRes = S_OK;
//1. extract selected pages (!note: page numbers are 1-based)
_bstr_t bstrPath(L"..\\..\\sample2.pdf");
_bstr_t bstrParam(L"page2.pdf");
sRes = pIDocumentSplitter->ExtractPage(bstrPath, bstrParam, 2);
// 2. split the doc into 2 parts at page #2
// (!) Note: page numbers are 1-based
_bstr_t bstrPathInput(L"..\\..\\sample2.pdf");
_bstr_t bstrParam1(L"part1.pdf");
_bstr_t bstrParam2(L"part2.pdf");
sRes = pIDocumentSplitter->Split(bstrPathInput, bstrParam1, bstrParam2, 2);
// 3. merge page 2 extracted on step 1 along with base pdf
// Create the interface pointer.
_DocumentMergerPtr pIDocumentMerger(__uuidof(DocumentMerger));
//_bstr_t bstrRegName(L"DEMO");
pIDocumentMerger->put_RegistrationName(bstrRegName);
//_bstr_t bstrRegKey(L"DEMO");
pIDocumentMerger->put_RegistrationKey(bstrRegKey);
// merge 2 files into the 3rd one
_bstr_t bstrParamMerge1(L"page2.pdf");
_bstr_t bstrParamMerge2(L"..\\..\\sample2.pdf");
_bstr_t bstrParamMergeOutput(L"merged.pdf");
sRes = pIDocumentMerger->Merge2(bstrParamMerge1, bstrParamMerge2,bstrParamMergeOutput);
// finally release both instances
pIDocumentSplitter->Release();
pIDocumentMerger->Release();
// uninitialize ActiveX COM support
CoUninitialize();
return 0;
}
How to Merge Multiple PDF Documents in Visual Basic .NET
Check out the following code sample to merge multiple PDF documents in Visual Basic .NET.
Imports Bytescout.PDFExtractor
Imports System.Diagnostics
Class Program
Friend Shared Sub Main(args As String())
Dim inputFiles As String() = New String() {"sample1.pdf", "sample2.pdf", "sample3.pdf"}
Using merger As New DocumentMerger("demo", "demo")
merger.Merge(inputFiles, "result.pdf")
End Using
Process.Start("result.pdf")
End Sub
End Class
How to Merge Multiple PDF Documents in VBScript (Visual Basic 6)
See the following source code sample to learn how to merge multiple PDF documents in VBScript (Visual Basic 6).
' Create Bytescout.PDFExtractor.DocumentMerger object
Set merger = CreateObject("Bytescout.PDFExtractor.DocumentMerger")
merger.RegistrationName = "demo"
merger.RegistrationKey = "demo"
Dim inputFiles
inputFiles = Array("..\..\sample1.pdf", "..\..\sample2.pdf", "..\..\sample3.pdf")
merger.Merge inputFiles, "result.pdf"
Set merger = Nothing
Though all code snippets are simple and clearly demonstrate the PDF document merging process, let’s review the C# program snippet.
First of all, we’re loading “Bytescout.PDFExtractor” library, If you want to code along you need to have Bytescout SDKs installed in your machine. You can get Bytescout SDKs from this link.
using Bytescout.PDFExtractor;
We are creating an instance of “DocumentMerger” class and passing registration name and key as constructor parameters to it. In this demo, we’re using demo keys, which have their limitations. If you’re using it in production then you need to use your actual keys received upon signing up.
using (DocumentMerger merger = new DocumentMerger("demo", "demo")
Next, we’re passing the input files array and specifying the output file location.
merger.Merge(inputFiles, "result.pdf");
And lastly, we’re opening the result file with the default associated application.
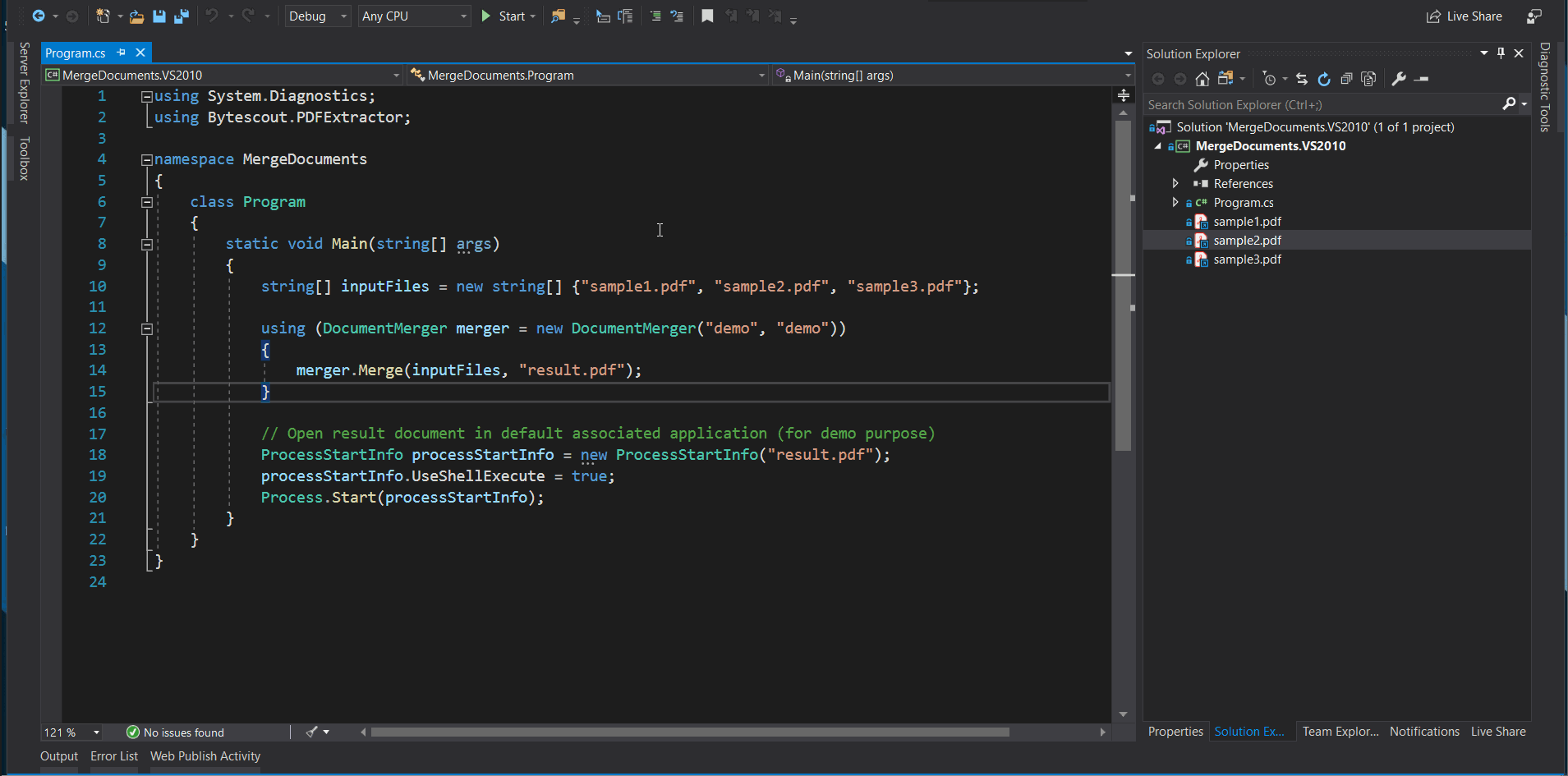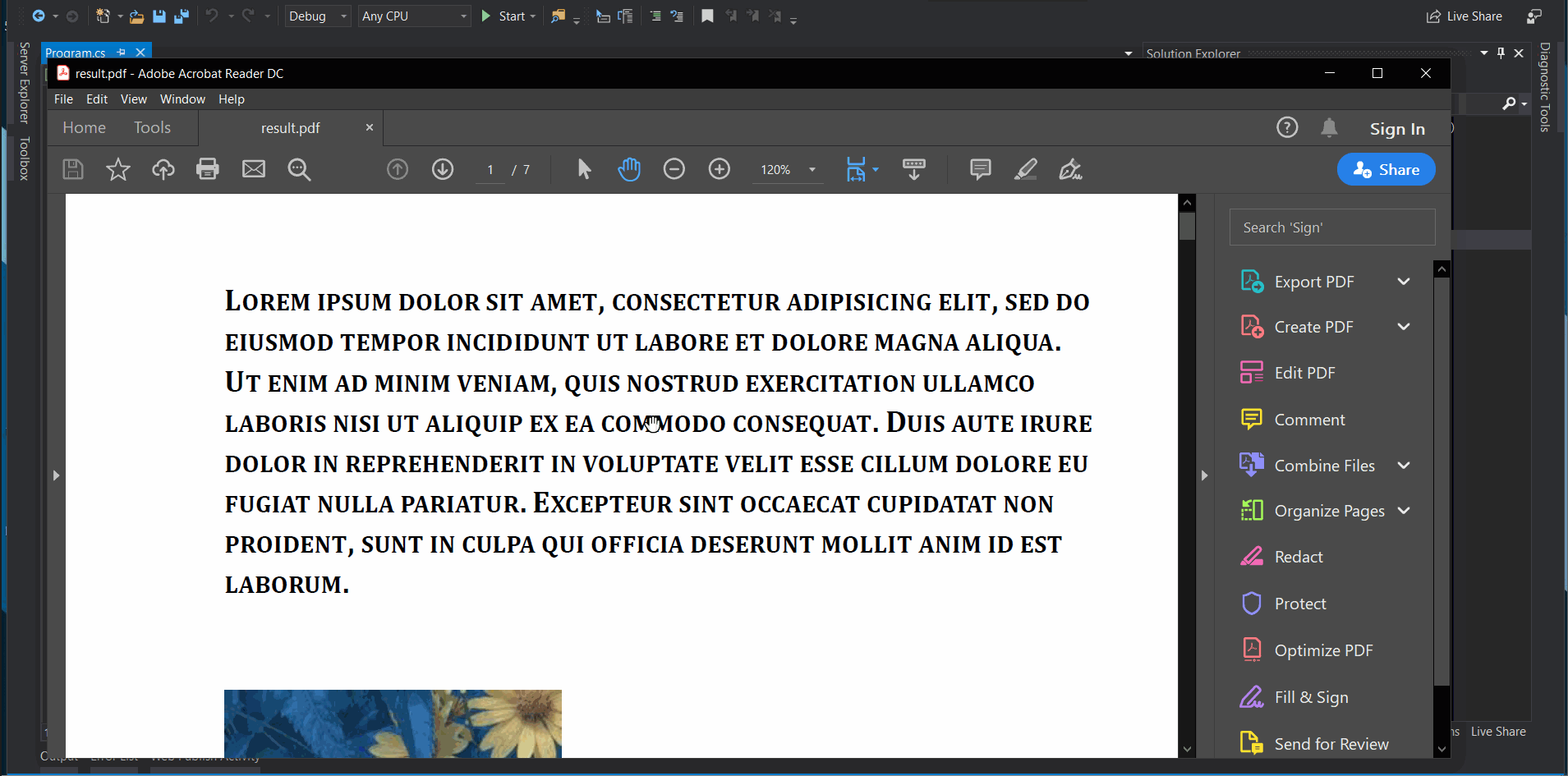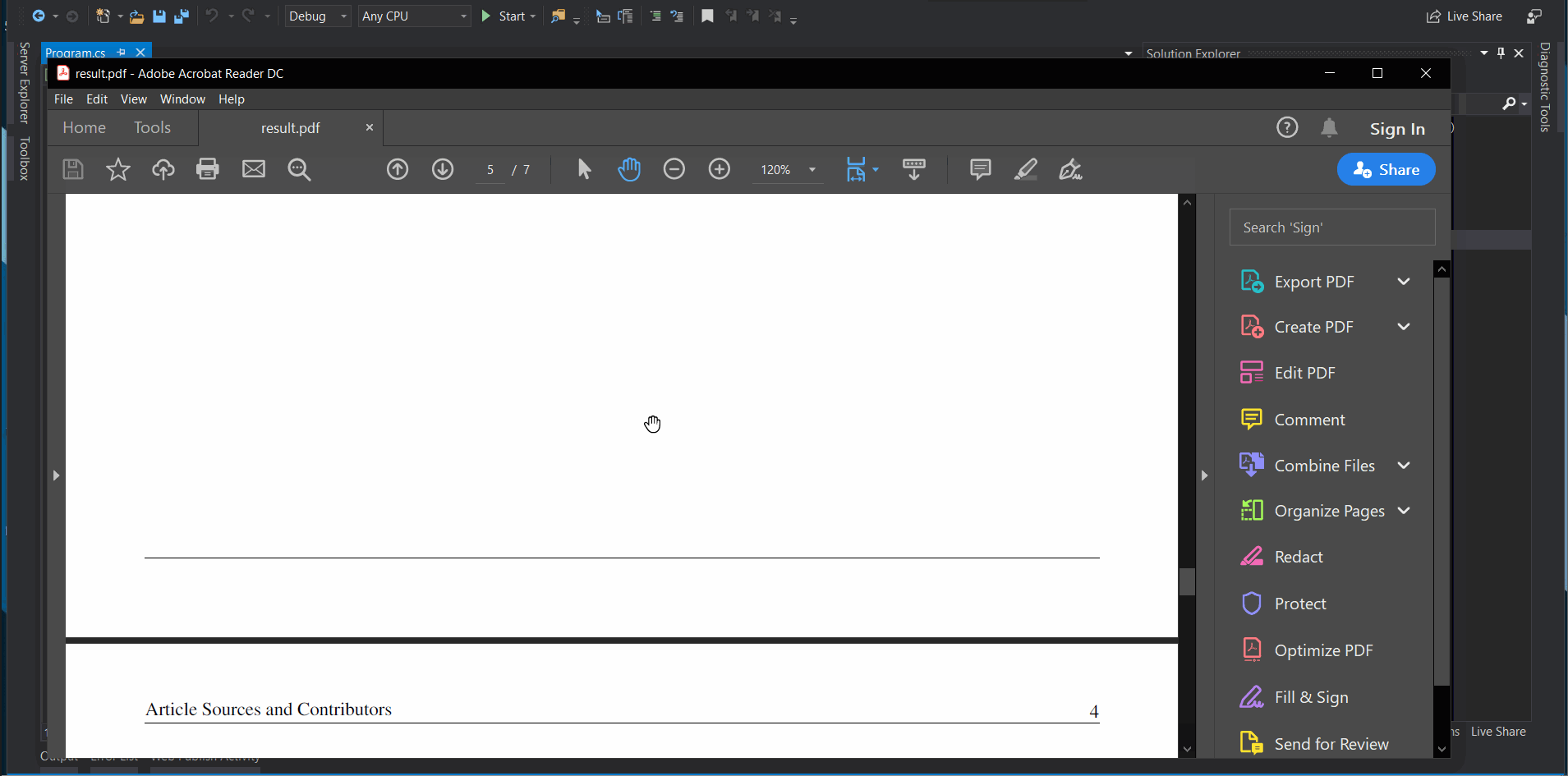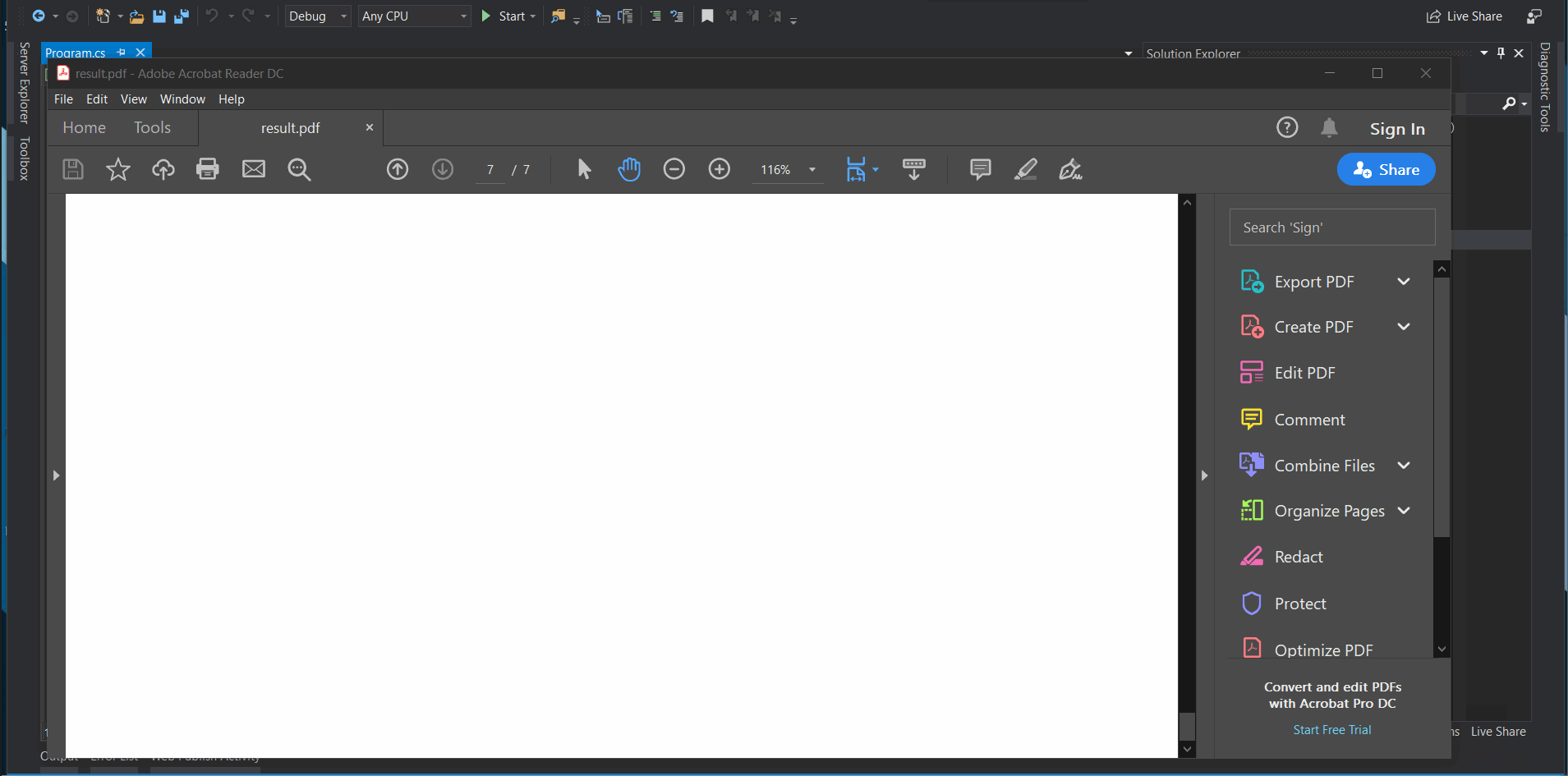
Program output looks like below in action.
That’s all guys. I hope you get an idea of how to merge PDF documents with ByteScout SDKs.
How to Merge PDF Files using ByteScout PDF Extractor SDK
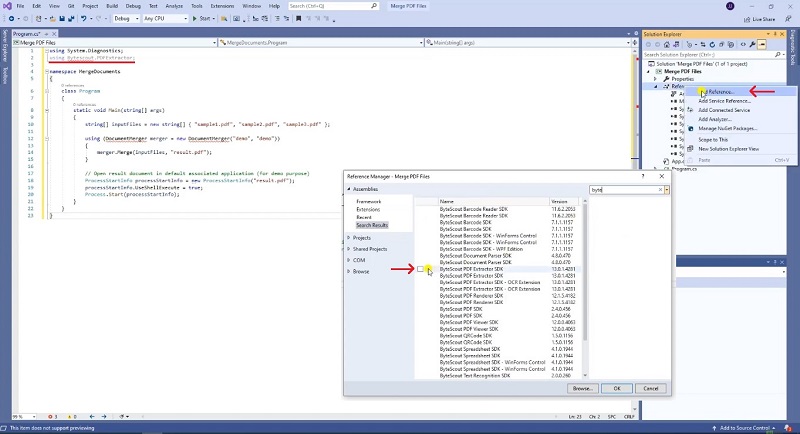
In this tutorial, we will merge PDF files using C#. Let’s copy the sample code and paste it into the Visual Studio editor. I added the sample code link in the description box below. To extract the PDF files, we will use the ByteScout PDF Extractor SDK. You can add a reference to the PDF Extractor SDK DLL and the Solution Explorer. Right-click on reference and select Add Reference. Look up the PDF Extractor SDK and add.
Then copy the sample files you’d like to merge. We will add our sample file in the solution explorer and set the copy to the output directory to ‘copy always’. Then add your registration name and registration key and their related properties accordingly. You can get your license details in the ByteScout dashboard. Then type the output file name.
Now let’s run the program and check out the output.