Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
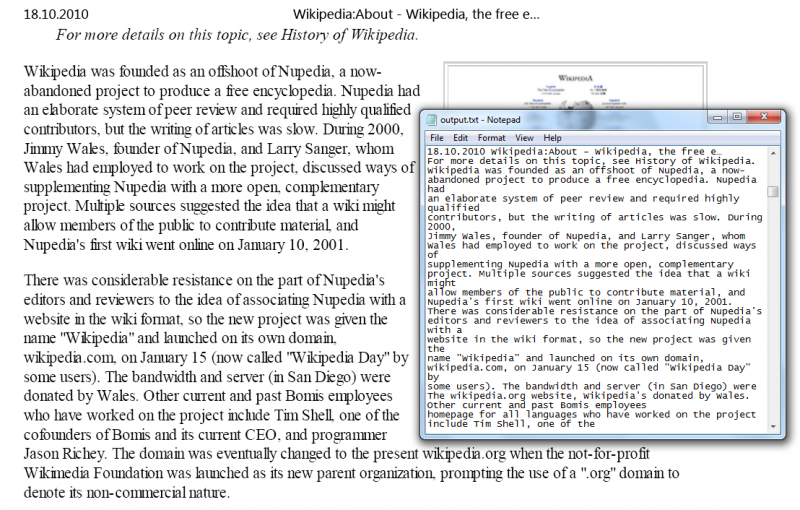
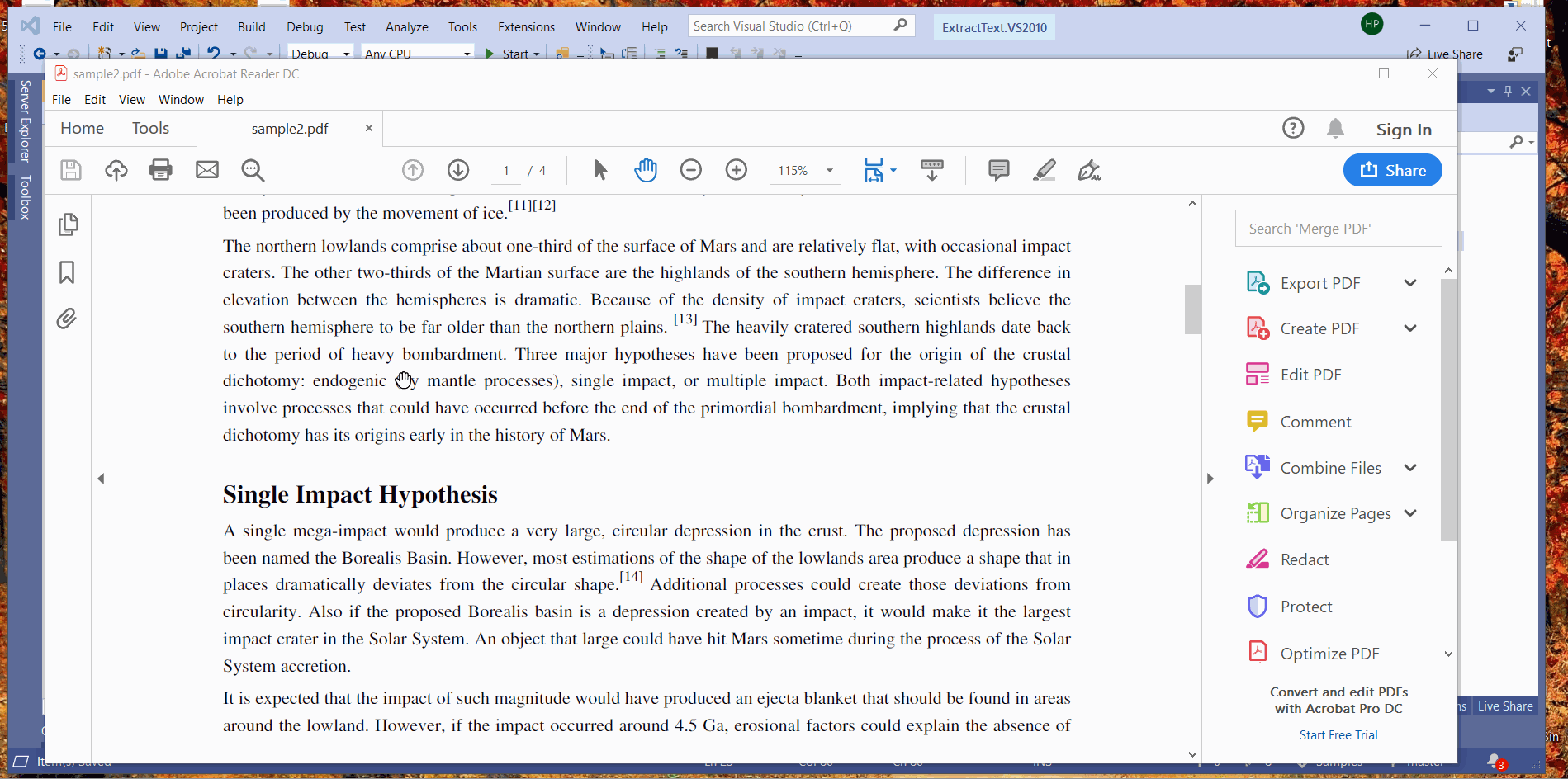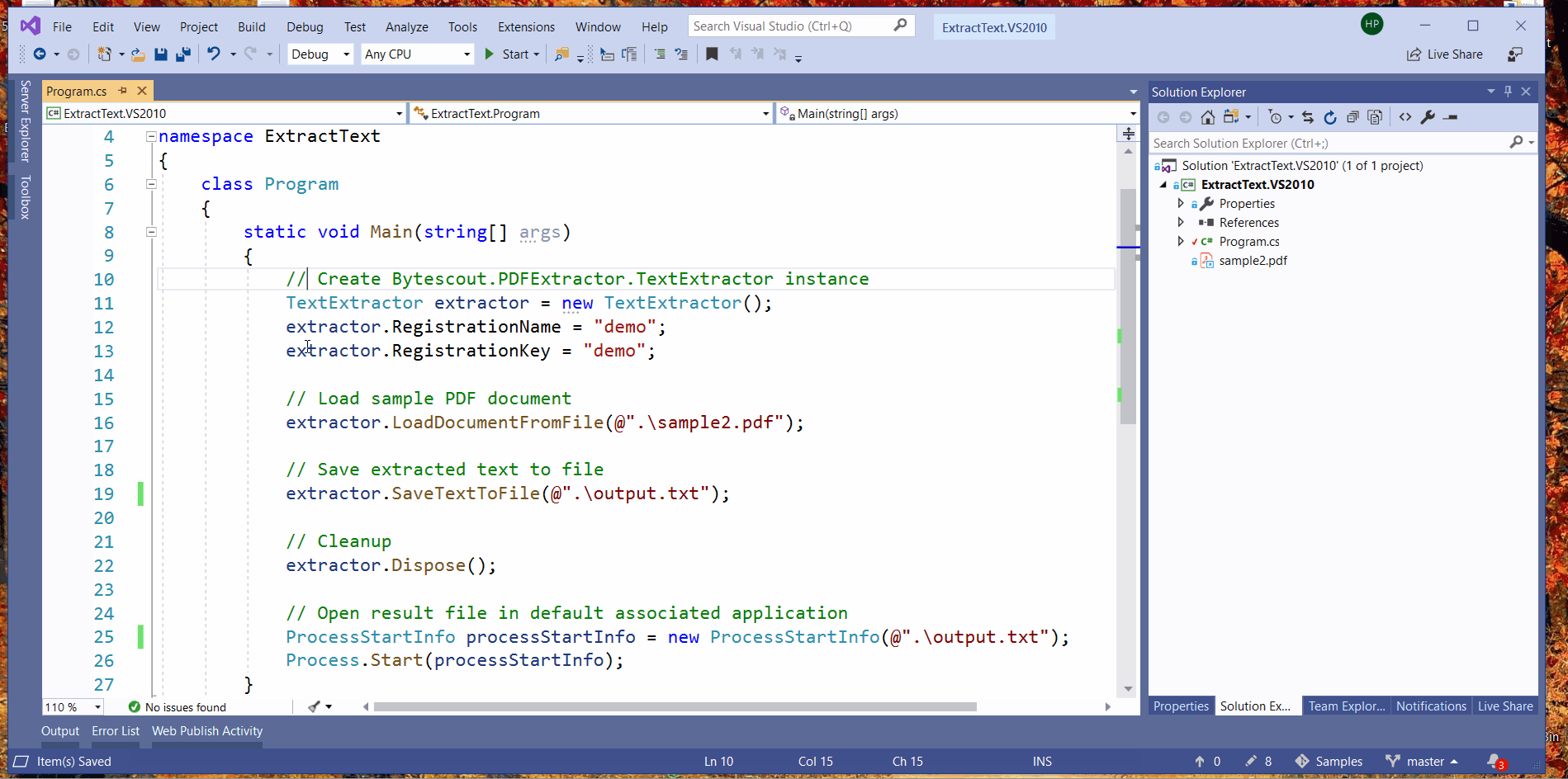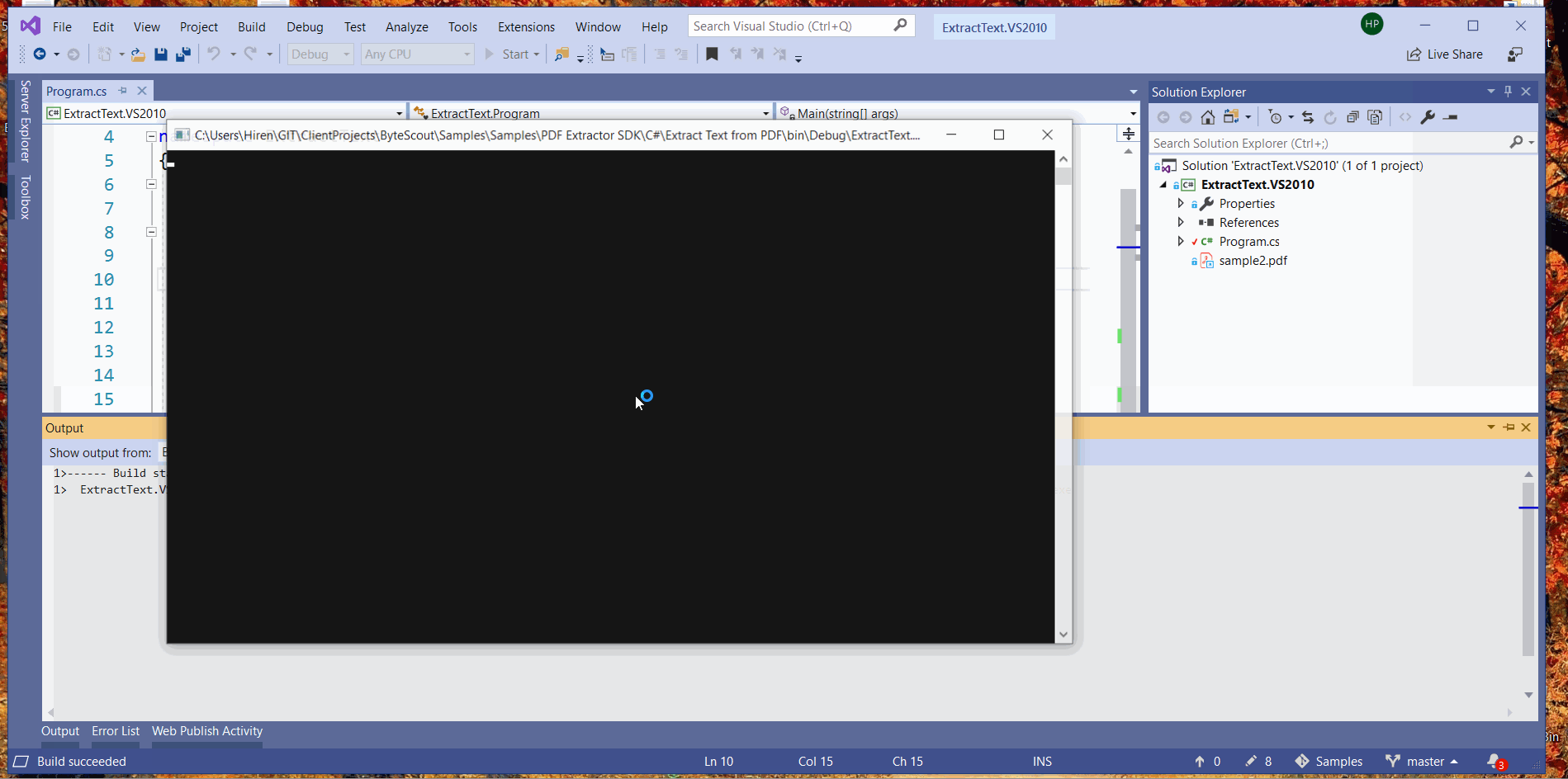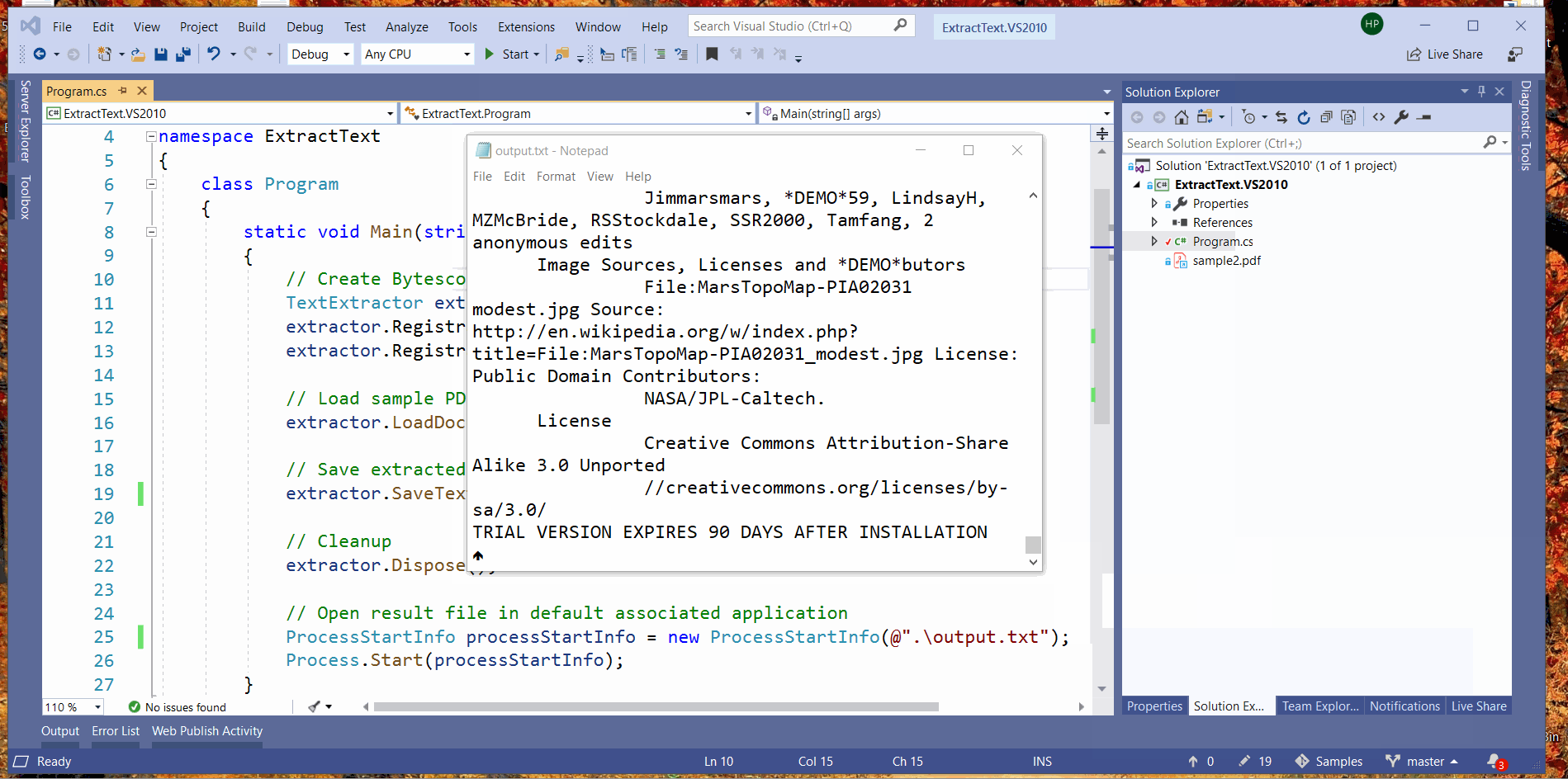
Input PDF file and output TXT file with extracted text (click to view full-size screenshot)
ASP.NET Source Code
Use this ASP.NET source code snippet to extract text from PDF files with the help of ByteScout PDF Extractor SDK.
using System;
using System.Data;
using System.Configuration;
using System.Collections;
using System.IO;
using System.Web;
using System.Web.Security;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using System.Web.UI.HtmlControls;
using Bytescout.PDFExtractor;
namespace ExtractAllText
{
public partial class _Default : System.Web.UI.Page
{
protected void Page_Load(object sender, EventArgs e)
{
// This test file will be copied to the project directory on the pre-build event (see the project properties).
String inputFile = Server.MapPath("sample2.pdf");
// Create Bytescout.PDFExtractor.TextExtractor instance
TextExtractor extractor = new TextExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile(inputFile);
Response.Clear();
Response.ContentType = "text/html";
// Save extracted text to output stream
extractor.SaveTextToStream(Response.OutputStream);
Response.End();
}
}
}
C# Source Code
ByteScout PDF Extractor SDK can extract PDF text in a few easy steps – just copy-paste this C# source code into your project.
using System;
using Bytescout.PDFExtractor;
namespace ExtractAllText
{
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.TextExtractor instance
TextExtractor extractor = new TextExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile("sample2.pdf");
// Save extracted text to file
extractor.SaveTextToFile("output.txt");
// Open output file in default associated application
System.Diagnostics.Process.Start("output.txt");
}
}
}
VB.NET Source Code
Use this VB.NET source code sample to extract text from PDF documents via ByteScout PDF Extractor SDK.
Imports Bytescout.PDFExtractor
Class Program
Friend Shared Sub Main(args As String())
' Create Bytescout.PDFExtractor.TextExtractor instance
Dim extractor As New TextExtractor()
extractor.RegistrationName = "demo"
extractor.RegistrationKey = "demo"
' Load sample PDF document
extractor.LoadDocumentFromFile("sample2.pdf")
' Save extracted text to file
extractor.SaveTextToFile("output.txt")
' Open output file in default associated application
System.Diagnostics.Process.Start("output.txt")
End Sub
End Class
VBScript Source Code
Copy-paste this VBScript source code snippet into your project to get text from PDF files by running the ByteScout PDF Extractor SDK.
' Create Bytescout.PDFExtractor.TextExtractor object
Set extractor = CreateObject("Bytescout.PDFExtractor.TextExtractor")
extractor.RegistrationName = "demo"
extractor.RegistrationKey = "demo"
' Load sample PDF document
extractor.LoadDocumentFromFile("....sample2.pdf")
' Save extracted text to file
extractor.SaveTextToFile("output.txt")
' Open output file in default associated application
Set shell = CreateObject("WScript.Shell")
shell.Run "output.txt", 1, false
Set shell = Nothing
Set extractor = Nothing
Program Output is as below:
Though the source code is pretty simple and straight forward, Let’s analyze it briefly.
After creating an instance we need to provide the registration key and name, which we’ll get upon registration for Bytescout SDK.
2. Load PDF document
extractor.LoadDocumentFromFile("sample2.pdf");
Here we’re simply loading the input PDF document. There are different versions of this method for different scenarios like loading password protected pdf, loading only a few pages of pdf document, etc. We can also use the “LoadDocumentFromStream” method to load documents from memory or any other stream data.
3. Save extracted text to file
extractor.SaveTextToFile("output.txt");
In this step, we’re performing text extraction along with saving it to the output file. If we want to save the output to stream then we can use the “SaveTextToStream” method.
That’s all guys. I hope you get an idea of how to use the Bytescout PDFExtractor assembly to extract text from PDF documents.