Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
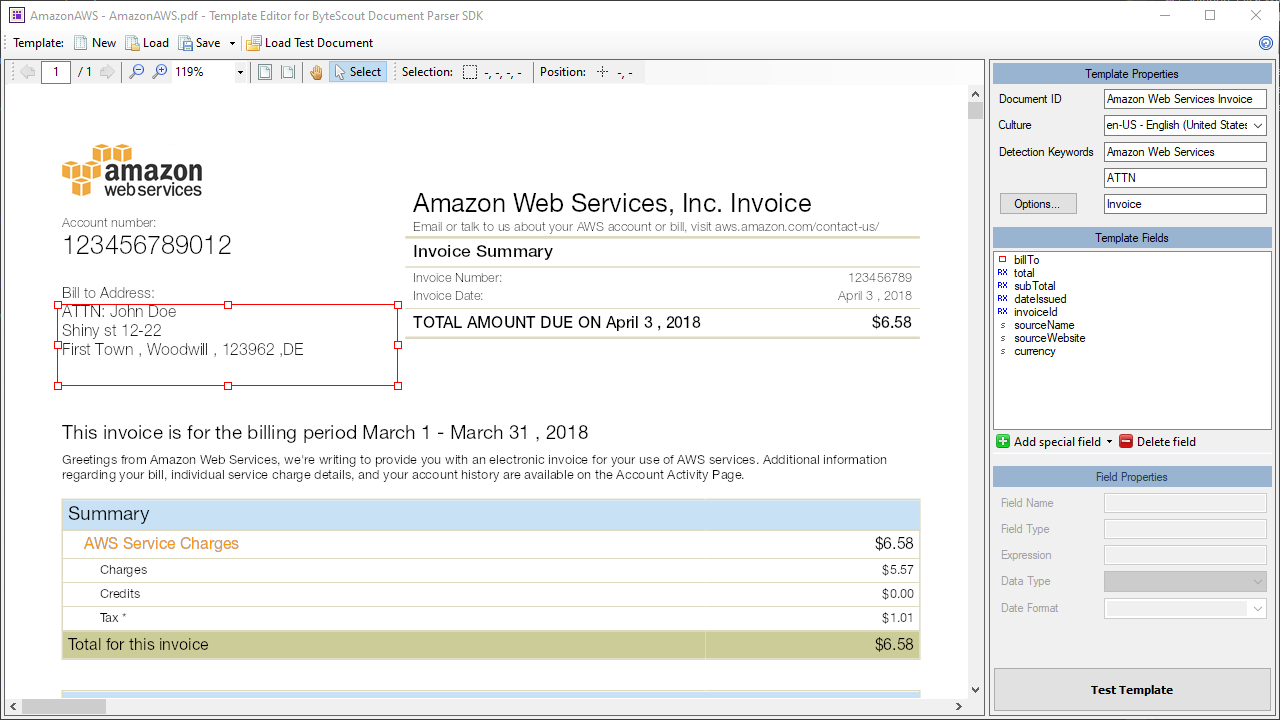
Document Parser SDK power your app with the reading of tables, fields, and unstructured text
from PDF and scans.
Key Benefits
Decrease time-to-market by with easy to make and easy to use extraction templates
No developers are required to create templates
Built-in invoice auto-parsing template
Re-use the library of pre-made templates that you can adapt to your needs
AI-powered PDF classification engine is included
Available as Web API, on-prem API, and library
Technical Features
AI-powered advanced PDF extractor engine on the core engine developed by ByteScout and battle-tested on millions of documents;
No coding required Document Parser Template Editor (available as an online version and as offline desktop version);
Supports PDF, JPG, PNG, TIFF images as input;
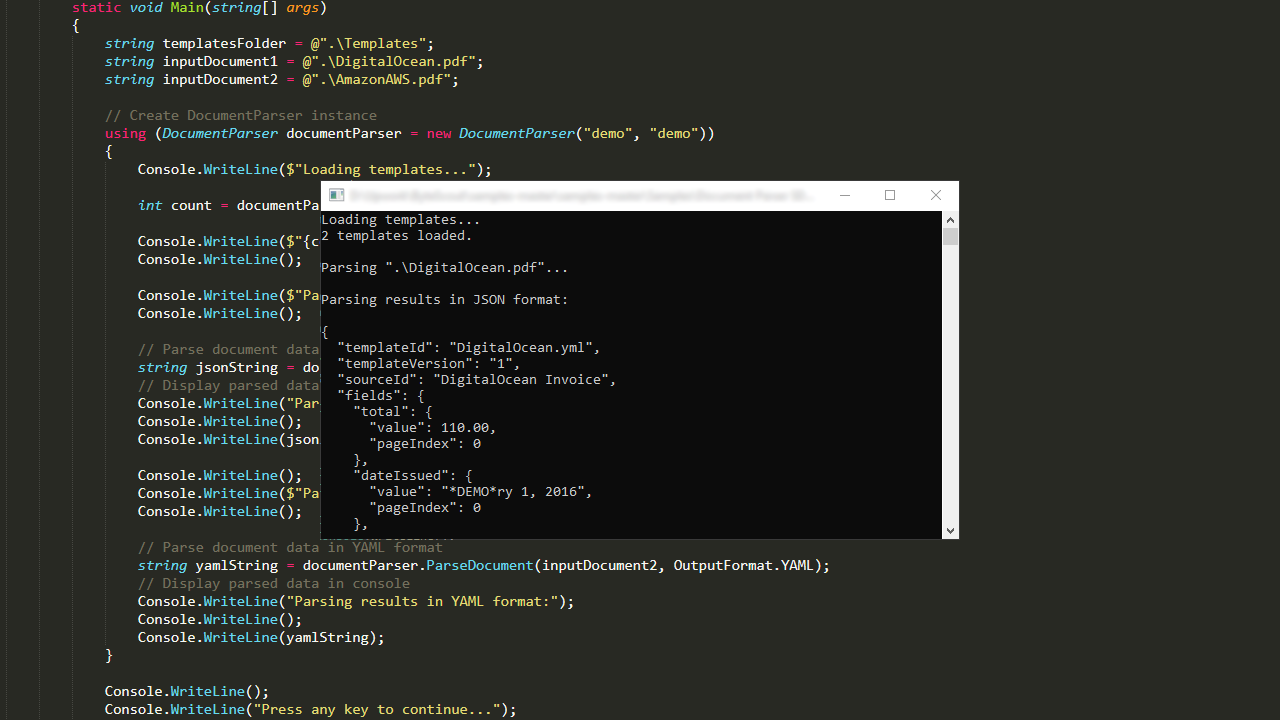
Extracts multiple documents inside a single PDF file;
Reads multiple tables located on the same pages;
Supports malformed and damaged PDF documents;
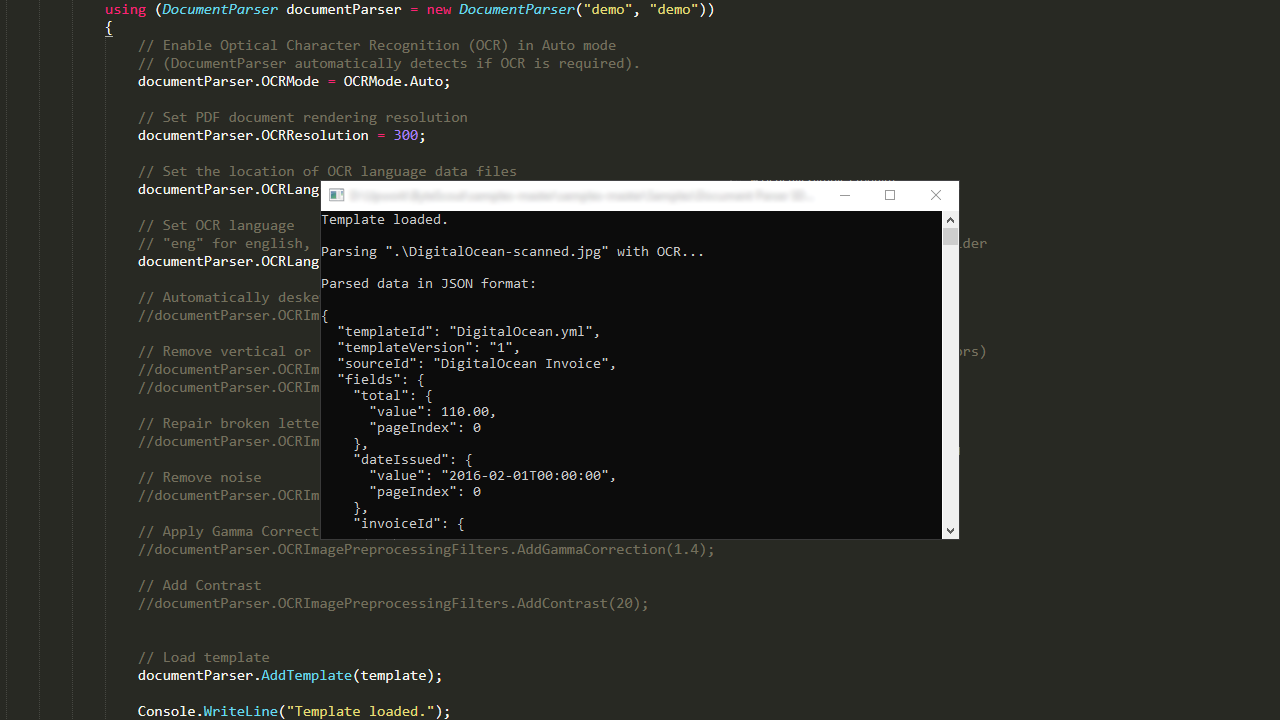
ML-powered OCR with document cleaning preprocessing filters for improved text recognition quality;
OCR (image to text) supports English, Spanish, Dutch, German, French, and dozens of other languages supported;
Mixed OCR languages are supported;
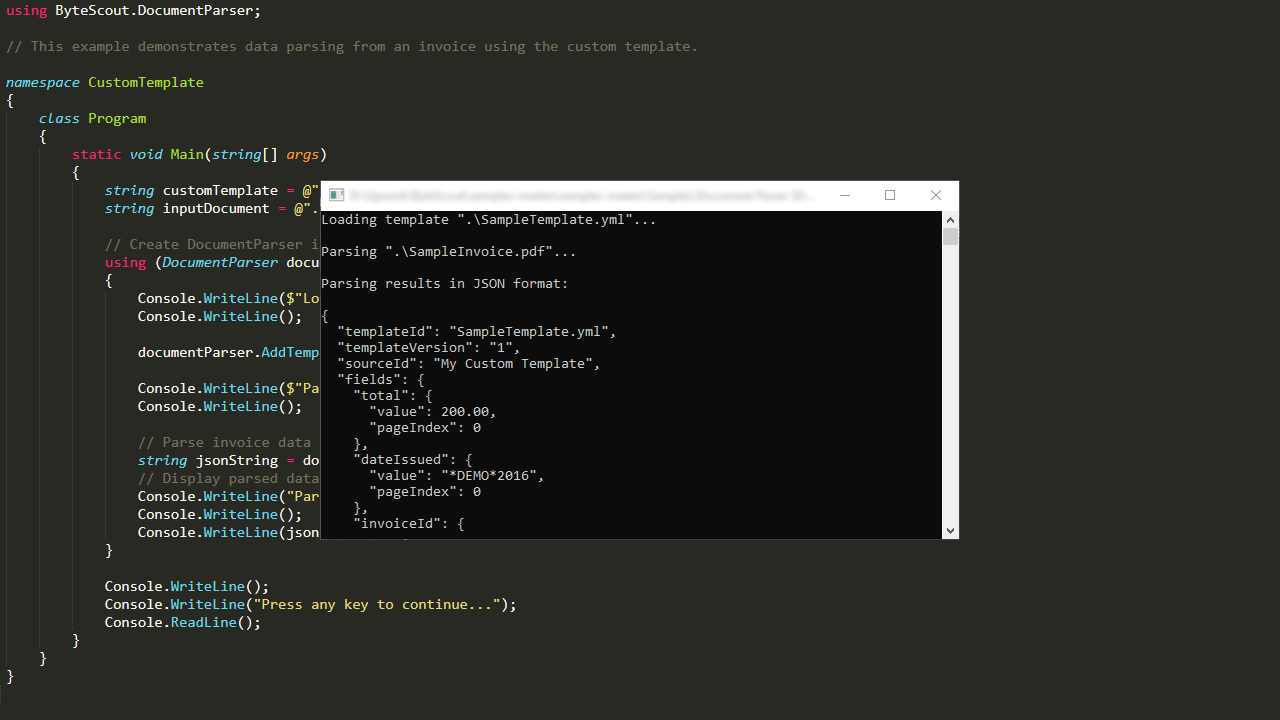
Data output in JSON, YAML, XML and CSV formats;
Available as Web API, on-prem API Server, on-prem library .NET and ASP.NET. Also available as ActiveX/COM object (through .NET Interop wrapper) for using from Delphi, VC++, VB6, VBScript, JScript, and other languages;