Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
Convert PDF to CSV tutorial shows how to convert PDF to Excel file in C# and Visual Basic .NET using PDF Extractor SDK.
ByteScout PDFExtractor SDK provides features to extract data from PDF and convert it to various formats such as Text, CSV, XML, Excel, etc. This SDK also provides support for scanned documents, as it has in-built OCR for various languages.
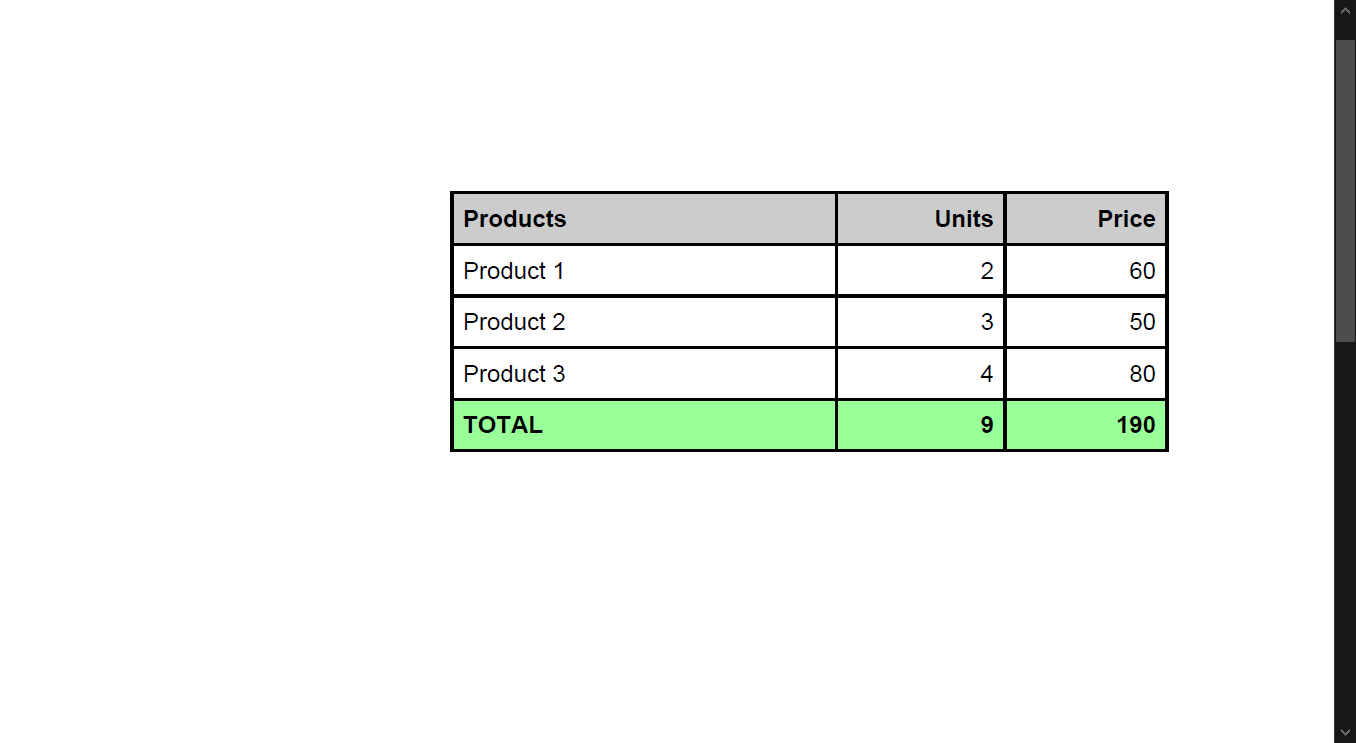
The following is the input document used in this program.
PDF Extractor SDK can be used to extract data from PDF files to different document formats (e.g. CSV file). Use the corresponding source code sample below for PDF to CSV conversion.
Take a look at the C# code sample needed for this task.
using System;
using System.Collections.Generic;
using System.Text;
using Bytescout.PDFExtractor;
using System.Diagnostics;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.CSVExtractor instance
CSVExtractor extractor = new CSVExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile("sample3.pdf");
//extractor.CSVSeparatorSymbol = ","; // you can change CSV separator symbol (if needed) from "," symbol to another if needed for non-US locales
extractor.SaveCSVToFile("output.csv");
Console.WriteLine();
Console.WriteLine("Data has been extracted to 'output.csv' file.");
Console.WriteLine();
Console.WriteLine("Press any key to continue and open CSV in default CSV viewer (or Excel)...");
Console.ReadKey();
Process.Start("output.csv");
}
}
}
VB.NET Code Sample
Take a look at the VB.NET code sample needed for this task.
Imports System
Imports System.Collections.Generic
Imports System.Text
Imports Bytescout.PDFExtractor
Imports System.Diagnostics
Namespace ConsoleApplication1
Class Program
Shared Sub Main(ByVal args As String())
' Create Bytescout.PDFExtractor.CSVExtractor instance
Dim extractor As New CSVExtractor()
extractor.RegistrationName = "demo"
extractor.RegistrationKey = "demo"
' Load sample PDF document
extractor.LoadDocumentFromFile("sample3.pdf")
'extractor.CSVSeparatorSymbol = "," // you can change CSV separator symbol (if needed) from "," symbol to another if needed for non-US locales
extractor.SaveCSVToFile("output.csv")
Console.WriteLine()
Console.WriteLine("Data has been extracted to 'output.csv' file.")
Console.WriteLine()
Console.WriteLine("Press any key to continue and open CSV in default CSV viewer (or Excel)...")
Console.ReadKey()
Process.Start("output.csv")
End Sub
End Class
End Namespace
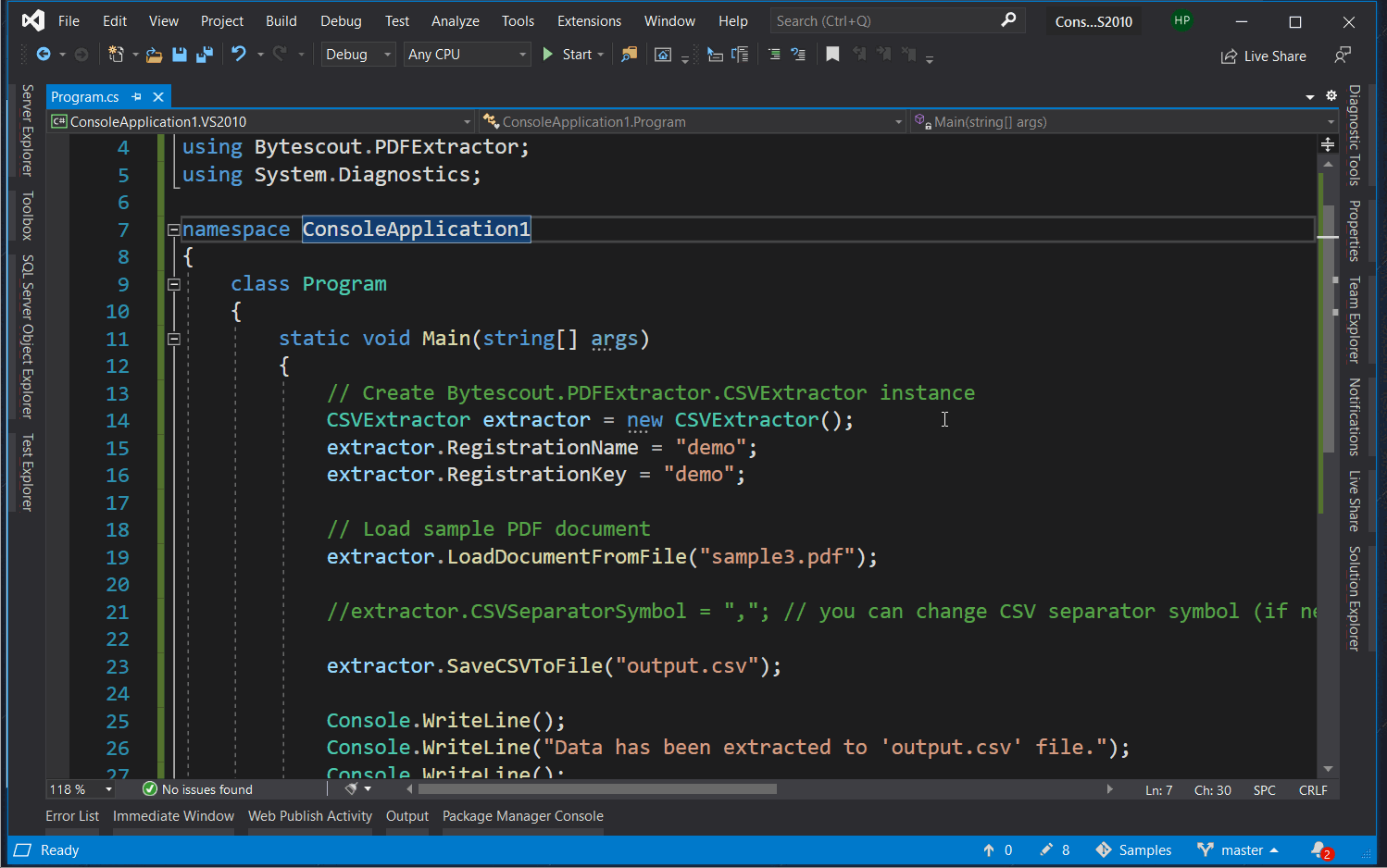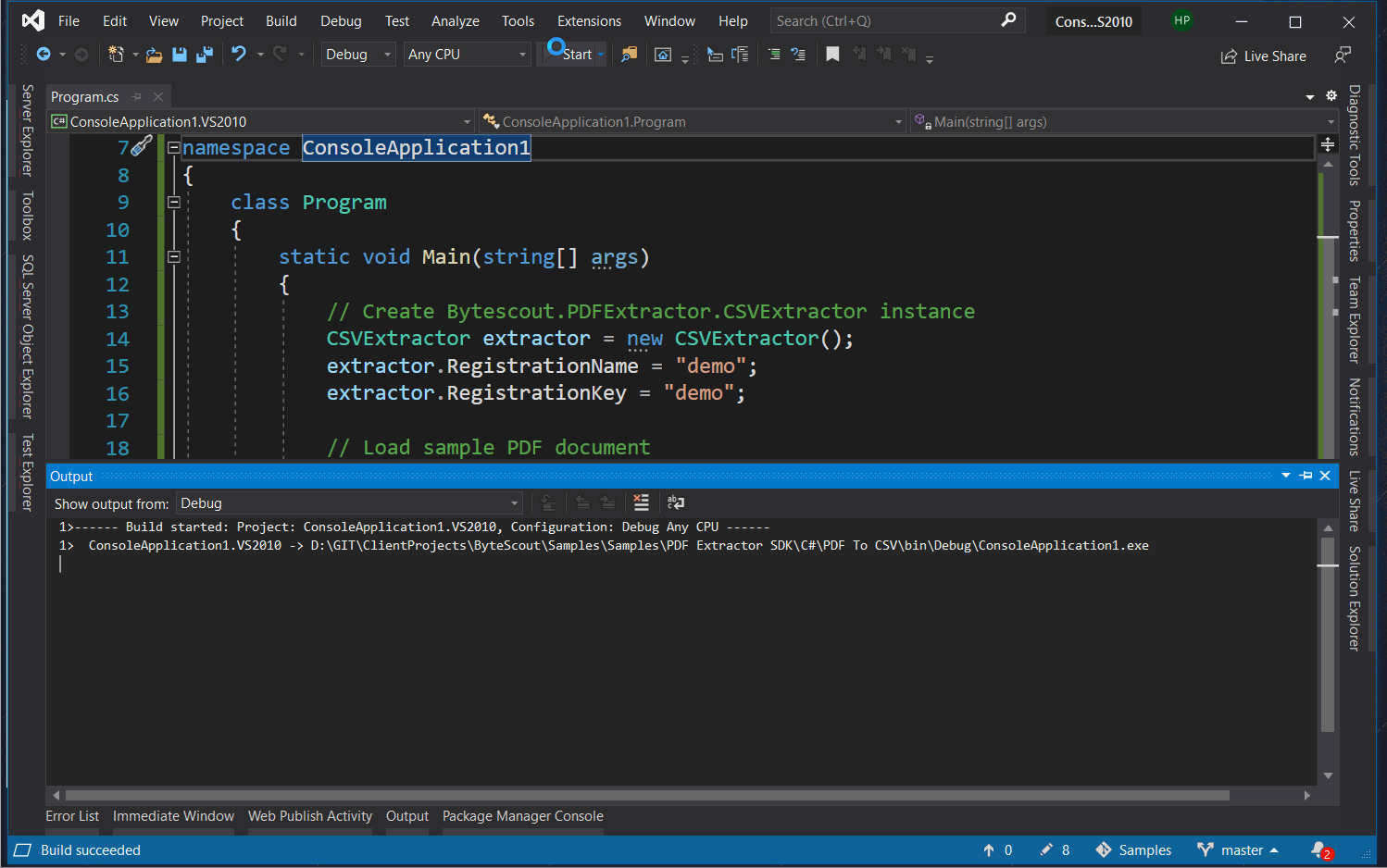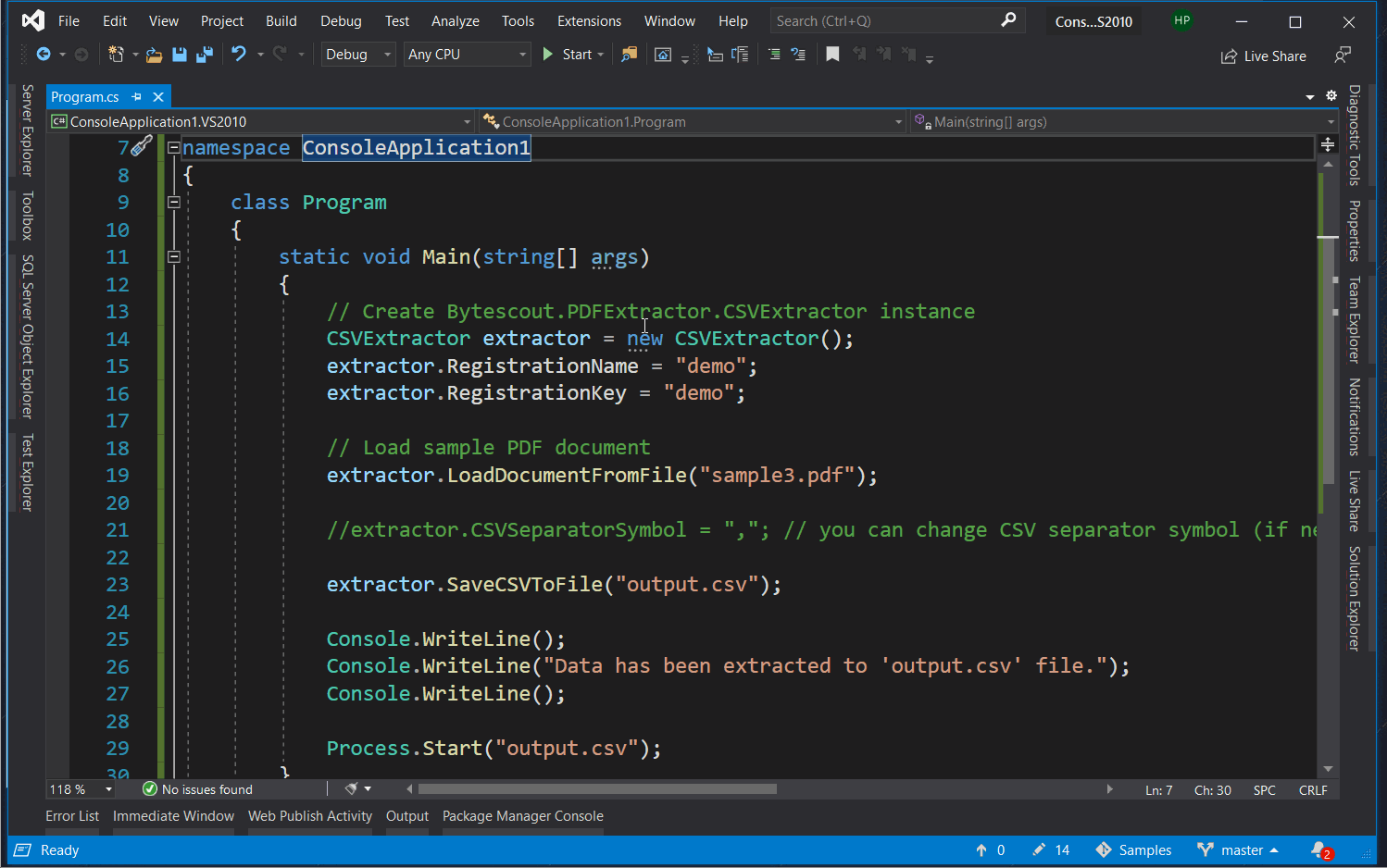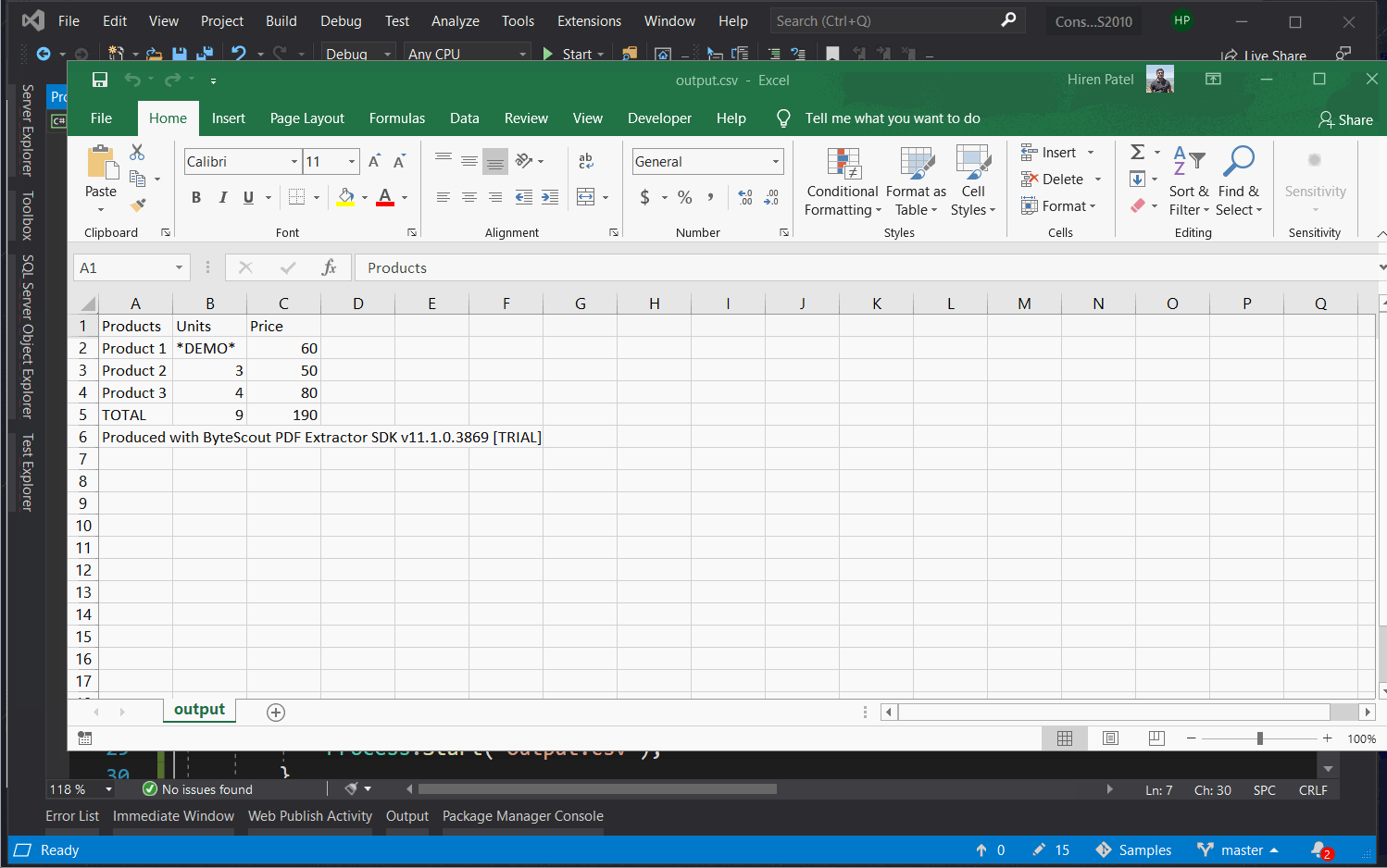
The output demo is as following.
Now that we’ve seen input and output screenshots, as well-reviewed program files, let’s analyze important code snippets. We’ll be reviewing code snippets from the C# language, as both C# and VB.NET samples have the same logic but minor language differences.
Creating CSVExtractor Instance
PDF Extractor assembly/namespace contains many classes providing different functionality. For example, CSVExtractor is being used in this program. This CSVExtractor class contains various methods/properties to efficiently execute or customize the CSV data conversation process.
In this code snippet, we’re creating an object of CSVExtractor and assigning the registration name and the key to it. Please Note: here we’re allocating demo key and names which will leave a watermark in the generated output. In the production environment, we should use keys received upon PDF Extractor SDK license purchase.
Providing Input Document
// Load sample PDF document
extractor.LoadDocumentFromFile("sample3.pdf");
We’re using the method LoadDocumentFromFile to load input PDF documents from file systems either from the local system or network accessed file path.
We can also provide input documents in form of Stream, which is very useful when PDF is being generated by the output of other functions. For this, we have to use the method LoadDocumentFromStream.
Extracting CSV Data
Now that all configuration is completed, we can generate output CSV and store it to the desired path by using the SaveCSVToFile method.
extractor.SaveCSVToFile("output.csv");
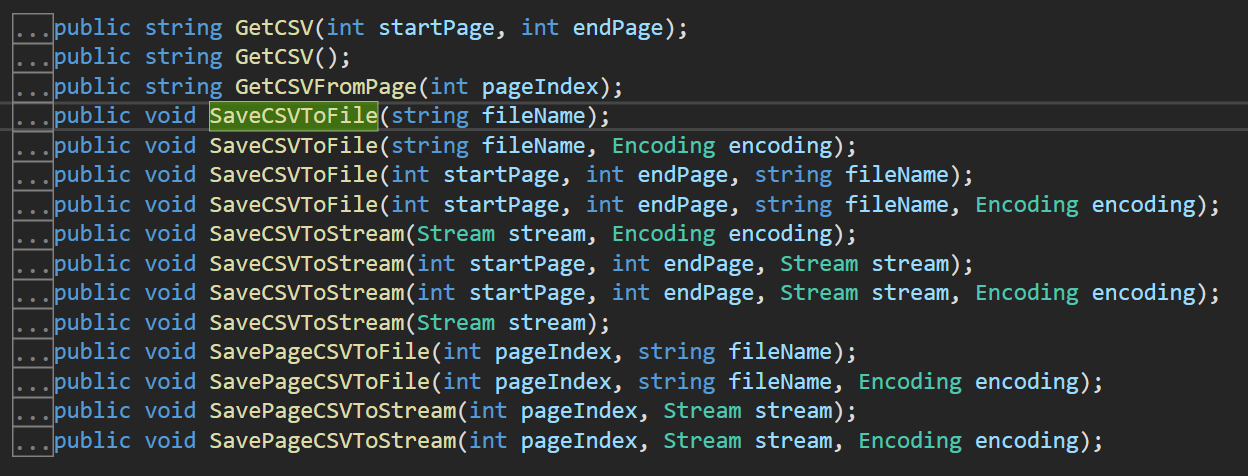
There are many methods available to further refine CSV output based on our requirements. For example, GetCSV, GetCSVFromPage, SaveCSVToStream, etc. Following is a screenshot of different output methods available with their overloaded version.
We can also customize generated CSV output by changing the CSV separator symbol. For this, we need to provide a separator delimiter to CSVSeperatorSymbol property.
//extractor.CSVSeparatorSymbol = ","; // you can change CSV separator symbol (if needed) from "," symbol to another if needed for non-US locales
That’s all guys! It’s how easy to extract data to CSV format with ByteScout PDFExtractor SDK. To get more out of this article, please try this program on your machine. The only requisite is that SDKs needed to be installed on your machine. Please refer following Links to get SDK: