How to Find Text in PDF using Regex in C# using ByteScout PDF Extractor SDK
Write code in C# to find text in PDF using regex with this step-by-step tutorial
These source code samples are listed and grouped by the programming language and functions they use. ByteScout PDF Extractor SDK is the SDK that helps developers to extract data from unstructured documents, pdf, images, scanned, and electronic forms. Includes AI functions like automatic table detection, automatic table extraction and restructuring, text recognition, and text restoration from pdf and scanned documents. Includes PDF to CSV, PDF to XML, PDF to JSON, PDF to searchable PDF functions as well as methods for low-level data extraction. It can find text in PDF using regex in C#.
You will save a lot of time on writing and testing code as you may just take the C# code from ByteScout PDF Extractor SDK to find text in PDF using regex below and use it in your application. In order to implement the functionality, you should copy and paste this code for C# below into your code editor with your app, compile and run your application. Further enhancement of the code will make it more vigorous.
Download the free trial version of ByteScout PDF Extractor SDK from our website with this and other source code samples for C#.
using System;
using Bytescout.PDFExtractor;
namespace FindText
{
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.TextExtractor instance
TextExtractor extractor = new TextExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile(@".\Invoice.pdf");
extractor.RegexSearch = true; // Enable the regular expressions
int pageCount = extractor.GetPageCount();
// Search through pages
for (int i = 0; i < pageCount; i++)
{
// Search dates in format 12/31/1999
string regexPattern = "[0-9]{2}/[0-9]{2}/[0-9]{4}";
// See the complete regular expressions reference at https://msdn.microsoft.com/en-us/library/az24scfc(v=vs.110).aspx
// Search each page for the pattern
if (extractor.Find(i, regexPattern, false))
{
do
{
Console.WriteLine("");
Console.WriteLine("Found on page " + i + " at location " + extractor.FoundText.Bounds);
Console.WriteLine("");
// Iterate through each element in the found text
foreach (ISearchResultElement element in extractor.FoundText.Elements)
{
Console.WriteLine(" Text: " + element.Text);
Console.WriteLine(" Font is bold: " + element.FontIsBold);
Console.WriteLine(" Font is italic: " + element.FontIsItalic);
Console.WriteLine(" Font name: " + element.FontName);
Console.WriteLine(" Font size: " + element.FontSize);
Console.WriteLine(" Font color: " + element.FontColor);
Console.WriteLine();
}
}
while (extractor.FindNext());
}
}
// Cleanup
extractor.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key to continue...");
Console.ReadLine();
}
}
}
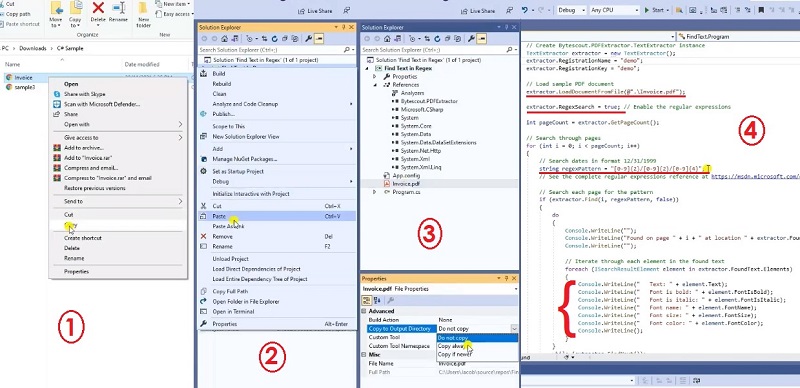
In this tutorial, we will find text in a PDF using Regex. Let’s copy the sample code and paste it into the Visual Studio editor. I added the sample code link in the description box below. To define Texting PDF, we will use the ByteScout PDF Extractor SDK. You can add a reference to the PDF Extractor SDK DLL in the solution explorer. Right-click on reference and select add reference. Look up the PDF Extractor SDK and add. Then add your registration name and registration key and their related properties accordingly. You can get your license details in the ByteScout dashboard.
We will add our sample file in the solution explorer and set the copy to the output directory to ‘copy always’. Then load the sample file in the loaded document from the file property. To use Regex, let’s set the ‘extractor.RegexSearch = true’. Then add the regex pattern to capture a text that matches the following pattern ‘[0-9]{2}/ [0-9]{2}/[0-9]{4}’ which is the format of our invoice date.
Once it finds the format on a page, it will return the text or the invoice date, its location in the PDF, its font name, font size, font color, and font style. Now run the program.