Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to Extract Text from a Scanned Document in Spanish using PDF Multitool
Having the ability to extract text from a document is really helpful. On the other hand, being able to extract Spanish text from a scanned document can only be done by a handful of applications. One such software is the PDF Multitool. It allows a user the capacity to extract text in various languages apart from Spanish. In addition, a user is able to perform various other tasks beyond text extraction from a scanned document. Therefore, a user can manipulate various types of documents as they need to.
Scanned documents are basically a pictorial representation of documents of digital media. As a result, a scanned document can be presented in various forms. The most common ways a scanned document can be stored are as a picture and as a PDF document.
An image can come in different types, qualities, and sizes. Some of the most used image types are GIF, JPEG, PNG, and TIFF. In most cases, users can decide the type of image during the process of scanning the document.
Likewise, a user can decide to have a document scanned as a PDF. A PDF file is one of the most popularly used documents at the moment. Many organizations and individuals prefer to use this type of file as it is more convenient and professional-looking. Nonetheless, a document scanned as a PDF still contains pictures. When the physical document is scanned, the images are embedded into the PDF file.
Whatever type of scanned document type used, the extraction process of text from the file is similar. In general, the text comes in different fonts and sizes. Since the text to be extracted comes from a scanned document, such text cannot be copied. Rather, it must be extracted using a tool like the PDF Multitool software. More importantly, the extractor can detect languages including Spanish.
How to Extract Text from Scanned Document
A person can simply use the PDF Multitool application to extract Spanish text from a scanned document. After launching the application, a pop-up window comes up.
A scanned document can be uploaded to the application via two options. In this case, a scanned document as a PDF file is uploaded, which is illustrated below.
Choose Extraction Settings
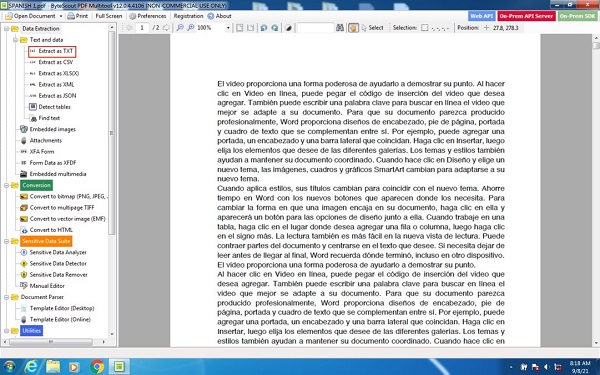
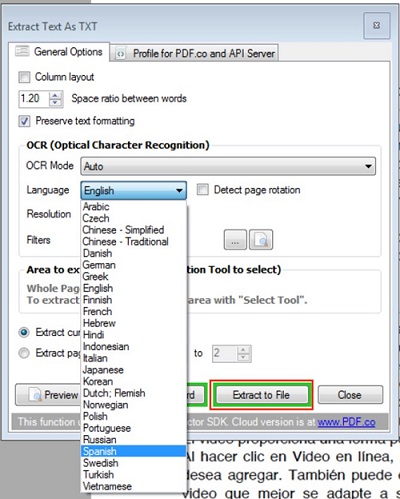
Once uploaded, the document appears on the screen. To extract text from the file, a user will select the ‘Extract as TXT’ option highlighted in the image. Immediately after selecting this option, a window comes up. A user is presented with several options amongst which is the language choice. A user can scroll through and select Spanish as the focal text for the extraction process. This option is shown below.
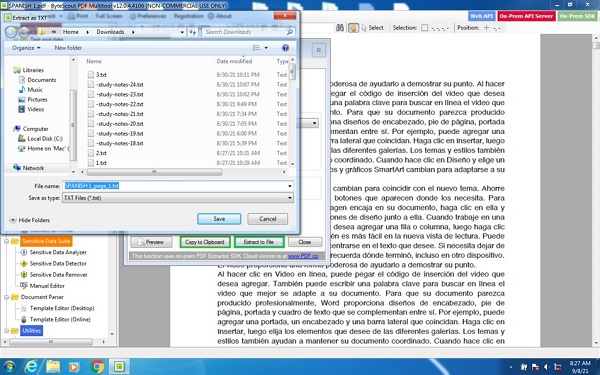
After selecting the language, a user can select the extract to file option. Clicking on this option pops out an option as seen below.
Save the Output
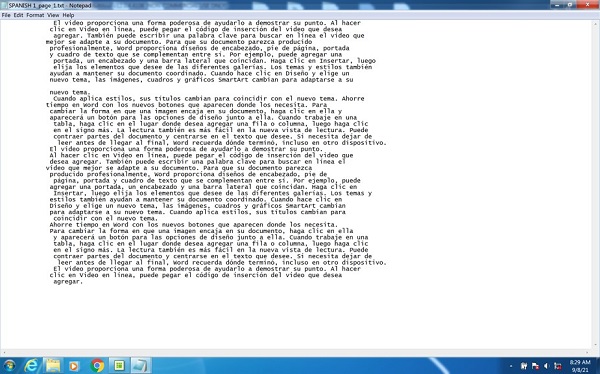
By selecting the save option, the scanned document is extracted and saved as text in Spanish. The text file in Spanish is shown below.