Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to Use OCR Modes and Extract Scanned PDF to Text using PDF Multitool?
In this tutorial, we will show you how to extract a scanned PDF file into Text using the PDF Multitool. We will also show how you can use the OCR Modes (Optical Character Recognition Modes) to help extract scanned PDF files.
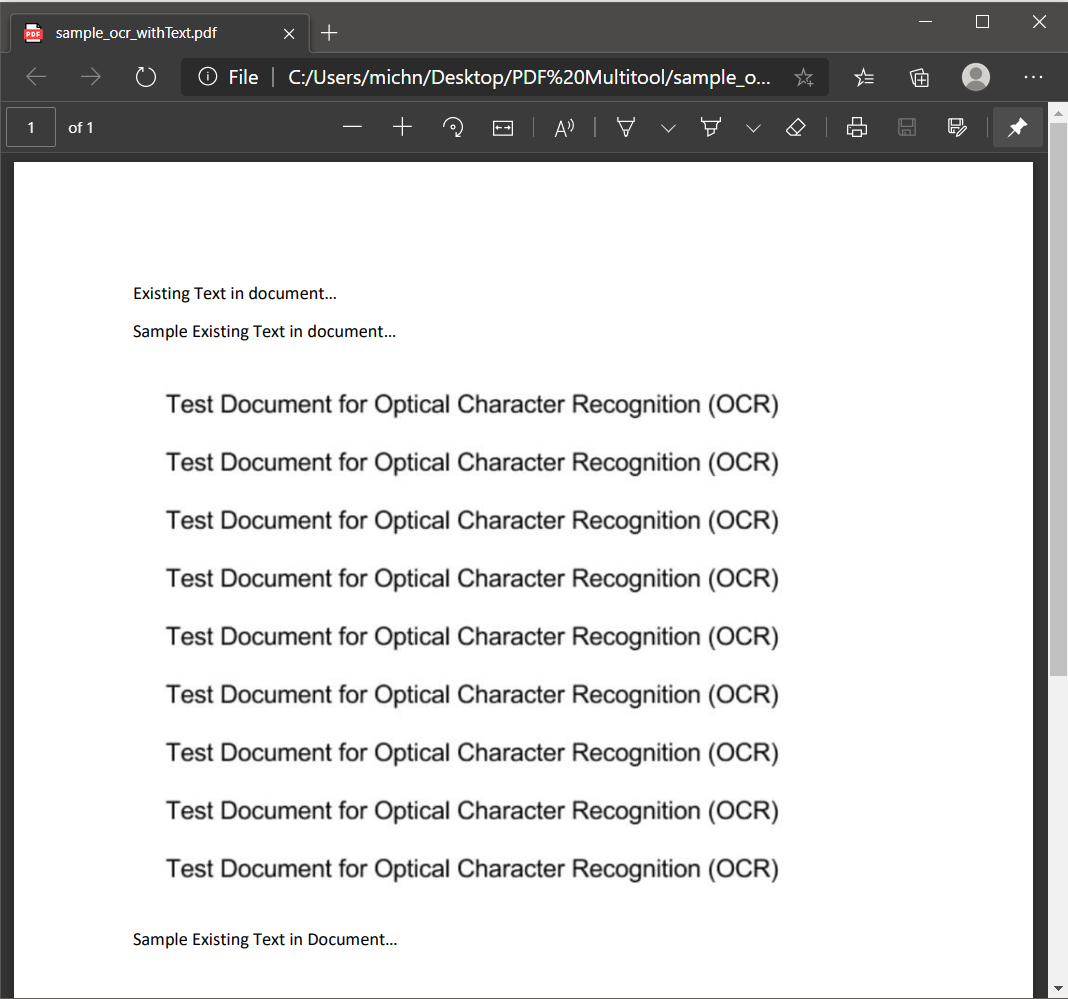
Our sample PDF file contains searchable and non-searchable text. You can easily distinguish the two by highlighting the text in the PDF.
Screenshot of Scanned PDF Source File
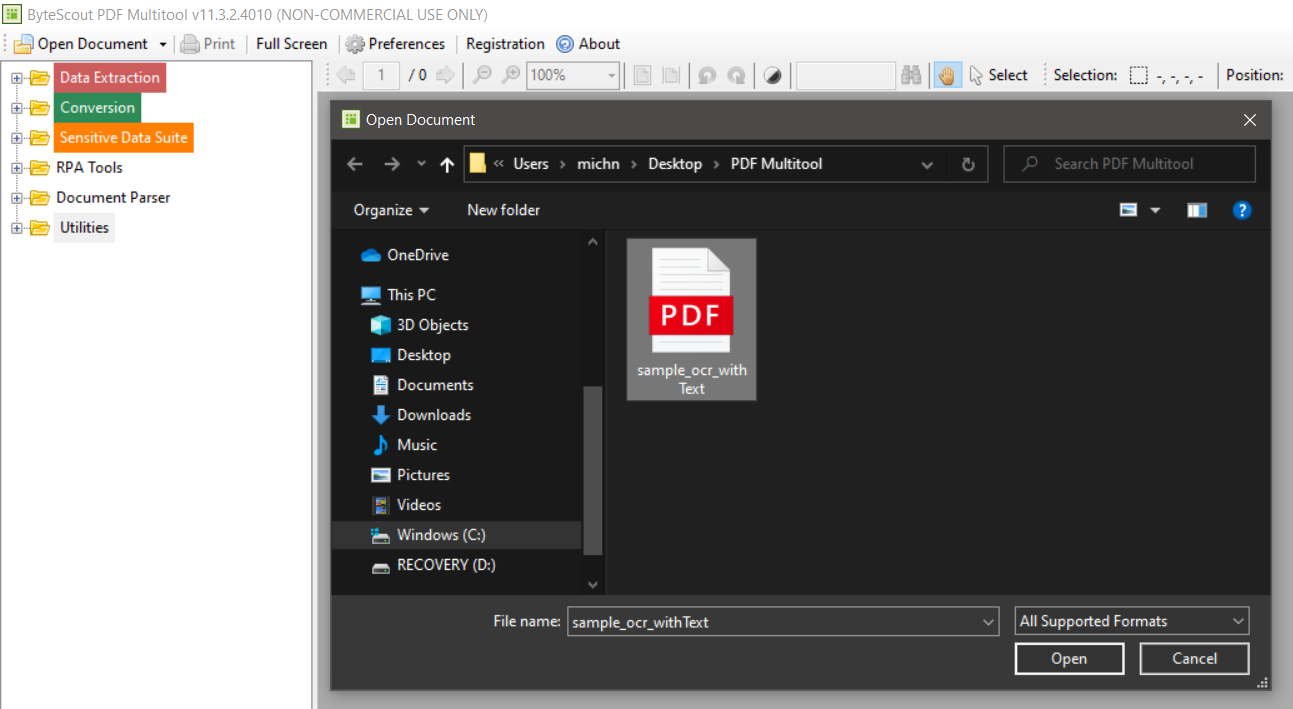
1. Open Sample File in the PDF Multitool
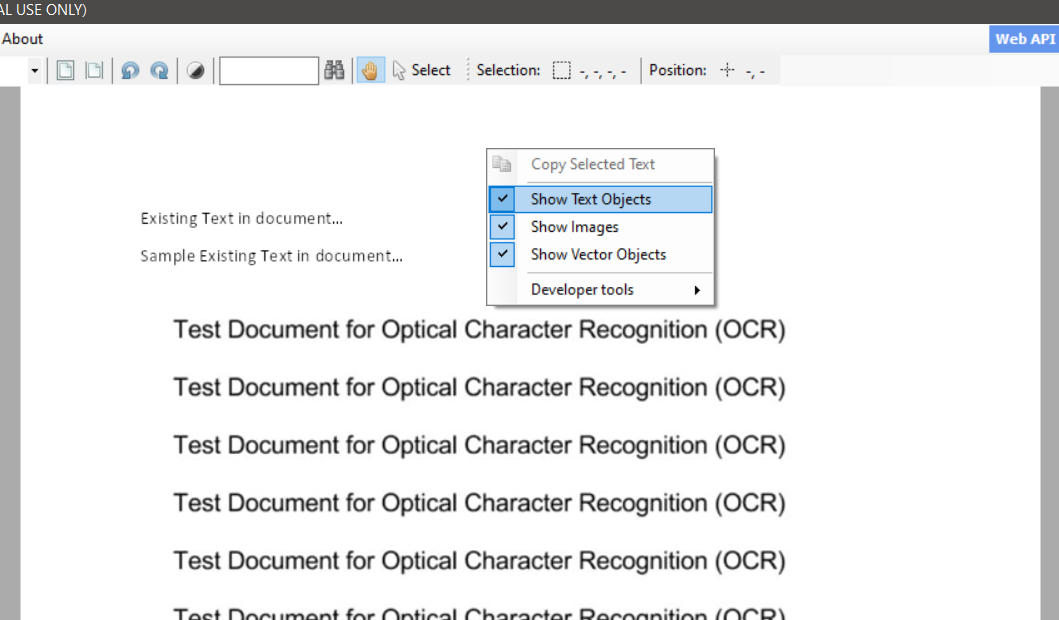
2. Identify the File by Toggling the Right Option
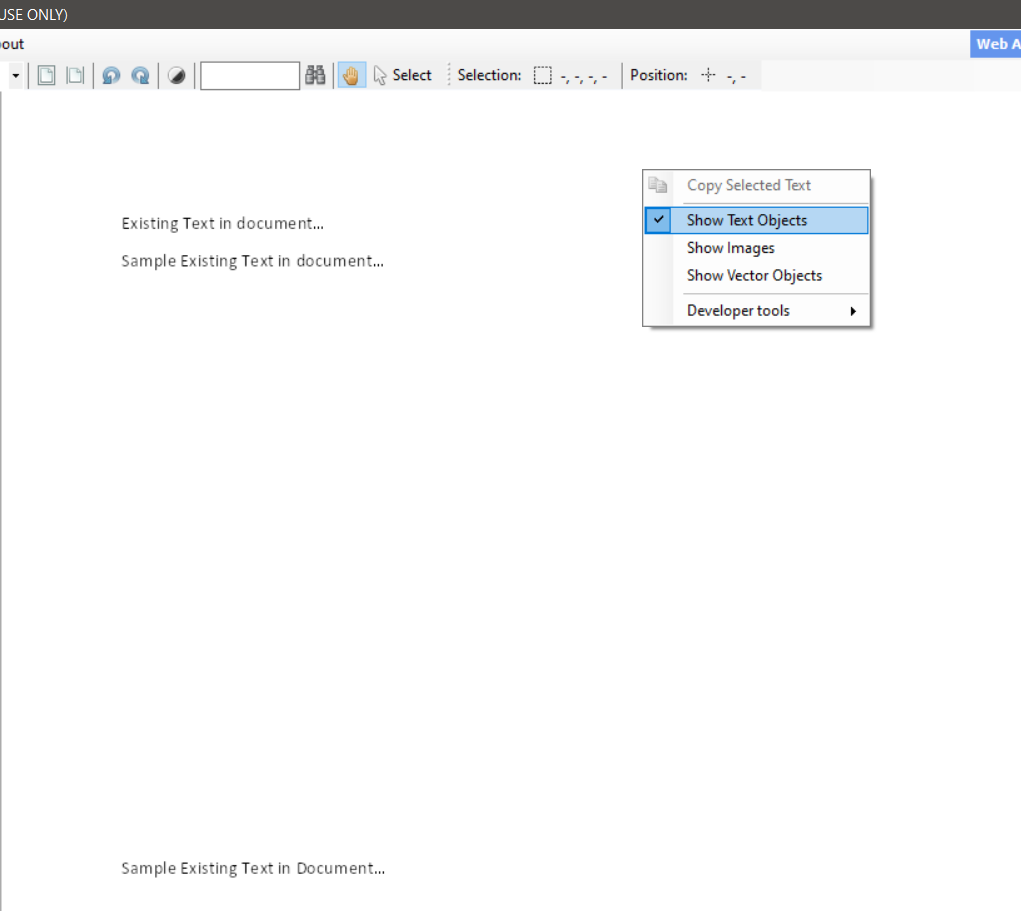
To easily identify the kind of file we have, we can toggle among three choices. Right-click on the file to see the three options.
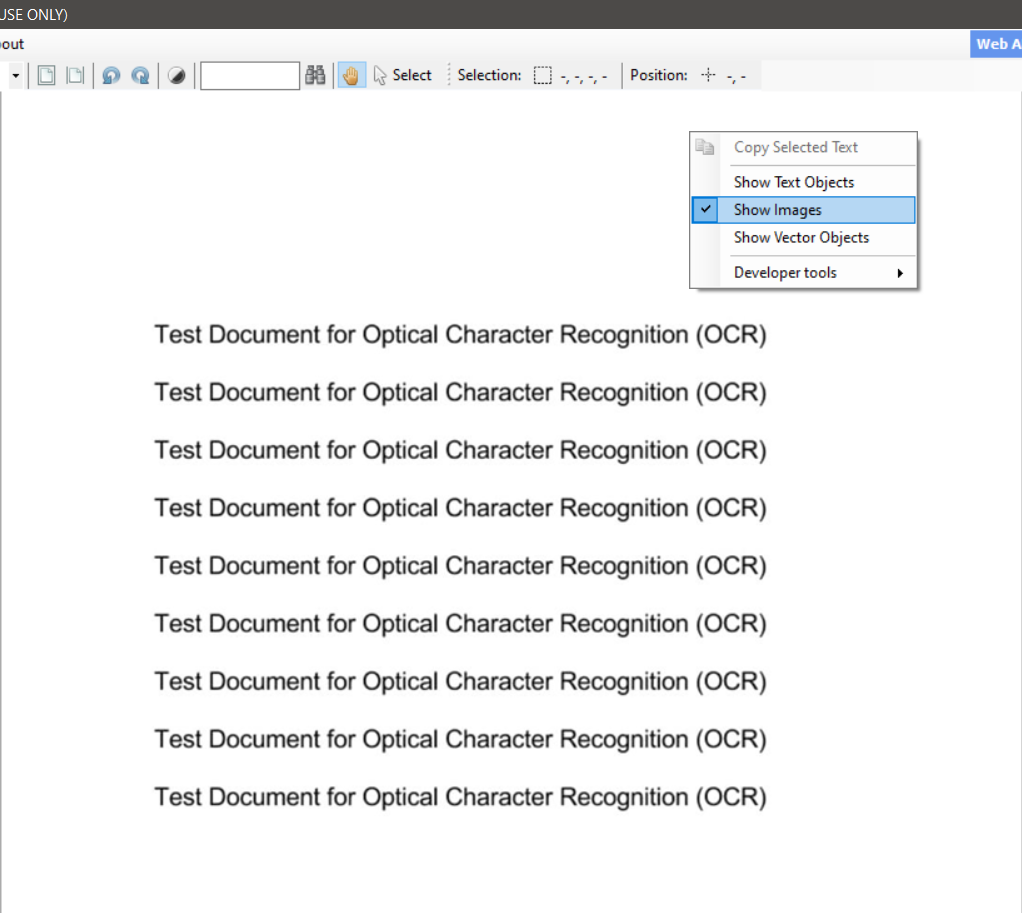
3. Check “Show Images”
When you check Show Images it will show you the image part of the document.
4. Check “Show Text Objects”
The same way with Show Text Objects, it will show you the text portion of the document. These toggle options make it easier for us to decide the right OCR Modes to use once we extract the file.
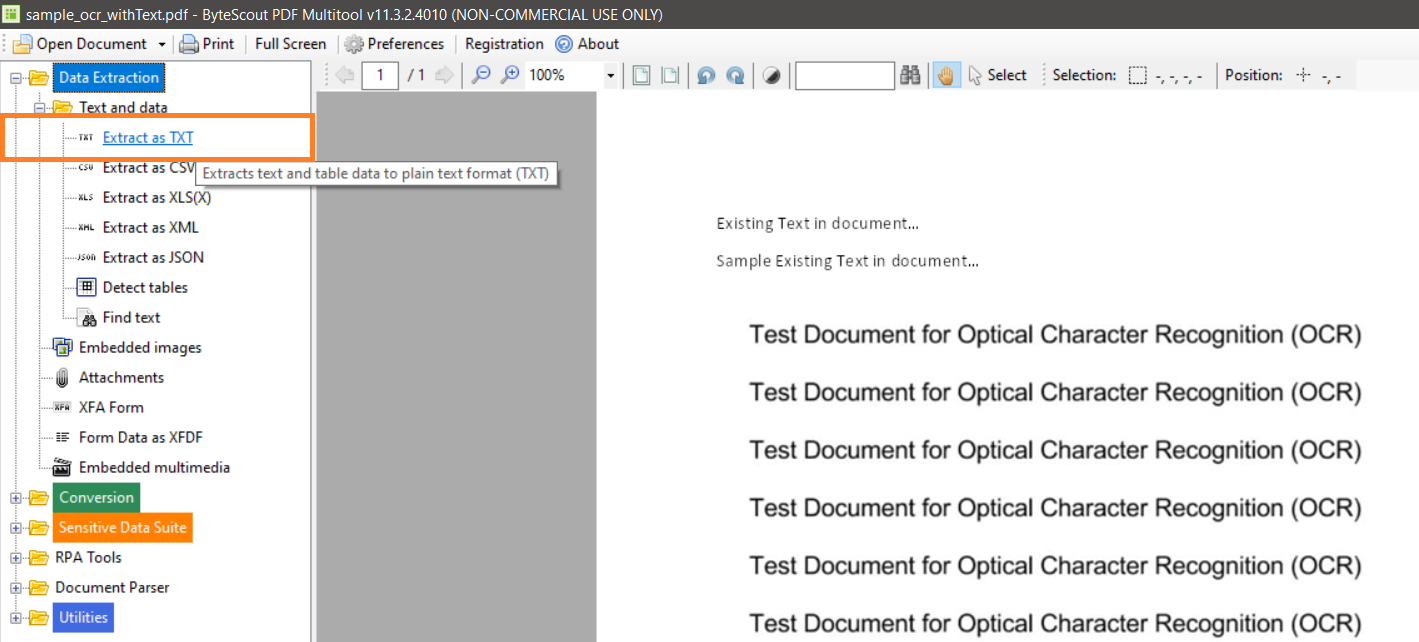
5. Click On Extract as TXT
On the left navigation panel, click on the Extract as TXT under the Data Extraction folder.
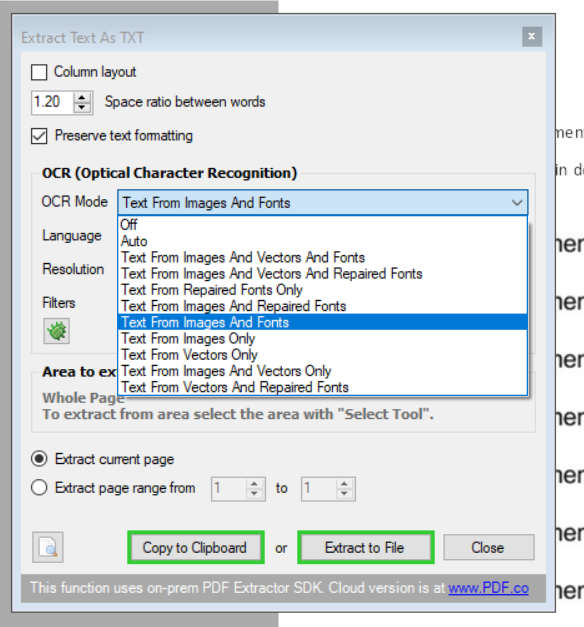
6. Select the Correct OCR Mode
There are 11 OCR Modes in the PDF Multitool and we can only use 1 OCR Mode at a time. We learned in the previous steps that we have text and images in our sample PDF file, so we will select the OCR Mode Text From Images and Fonts. Below is a description of how each OCR Mode works.
Off
No OCR is used.
Auto
Default OCR. Similar to TextFromImagesAndVectorsAndFonts but checks if the page only contains raster images to decide if OCR is needed. Only runs OCR if page contains very few text and one or more raster images. The result contains text objects produced from images and vector drawings.
TextFromImagesAndVectorsAndFonts
Always runs OCR to extract text from images and vector drawings (if any). See also .TextFromImagesAndFonts mode to read from objects except vector drawings. The result contains text objects from PDF and text objects produced from images and vector drawings using OCR functionality (if any).
TextFromImagesAndVectorsAndRepairedFonts
Special mode: extracts text from images, vector drawings, and repairs text from fonts fixing the incorrect encoding. Some PDF files contain visible text which is damaged when copied (appears as ? or other incorrect symbols when extracted or copied). This mode repairs damaged text like that using the OCR functionality. The result contains text objects from PDF, and text objects produced from images, and vector drawings using OCR functionality (if any).
TextFromRepairedFontsOnly
Special mode: repairs text objects with incorrect encoding using OCR functionality. Images and vectors are not processed in this mode. Some PDF files contains visible text which is damaged when copied (appears as ? or other incorrect symbols when extracted or copied). This mode repairs damaged text like this using OCR function. This mode returns repaired text objects only (no images or vector drawings are processed).
TextFromImagesAndRepairedFonts
Special mode: extracts text from raster images (but skips vector drawings) and repairs text objects with incorrect encoding Some PDF files contain visible text which is damaged when copied (appears as ? or other incorrect symbols when extracted or copied). This mode repairs damaged text like this using the OCR functionality. This mode returns repaired text objects, and text objects produced from raster images (no vector drawings are processed).
TextFromImagesAndFonts
Runs OCR to extract text from images (but skips vector drawings) plus the text objects. The result contains text objects from PDF, and text objects produced from images (but no vector drawings are processed) using OCR functionality.
TextFromImagesOnly
Runs OCR to extract text from images (but skips vector drawings) plus the text objects. The result contains text extracted from images only.
TextFromVectorsOnly
Runs OCR to extract text from vector drawings only. The result contains text objects from vector drawings only.
TextFromImagesAndVectorsOnly
Runs OCR to extract text from images and vector drawings only. No text from pdf objects is included. The result contains text objects from vector drawings only.
TextFromVectorsAndRepairedFonts
Runs OCR to extract text from repaired fonts and vector drawings only. The result contains repaired text and text objects from vector drawings only.
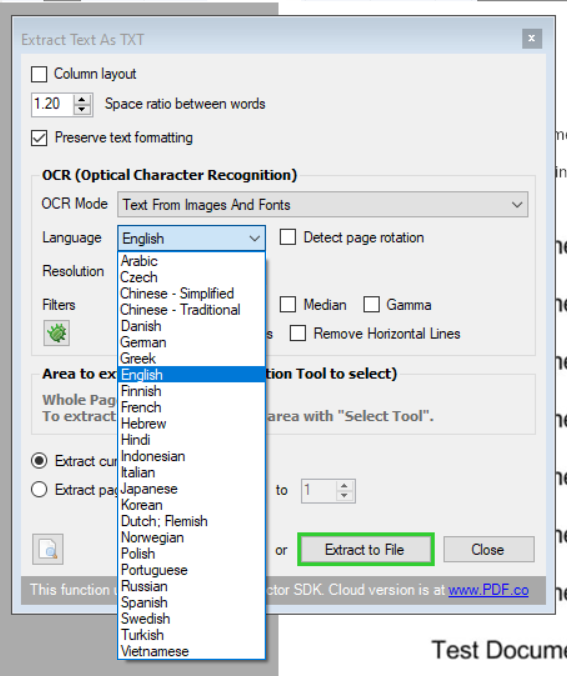
7. Select Document’s Language
The PDF Multitool supports several languages. Select the document’s language to get a more accurate result.
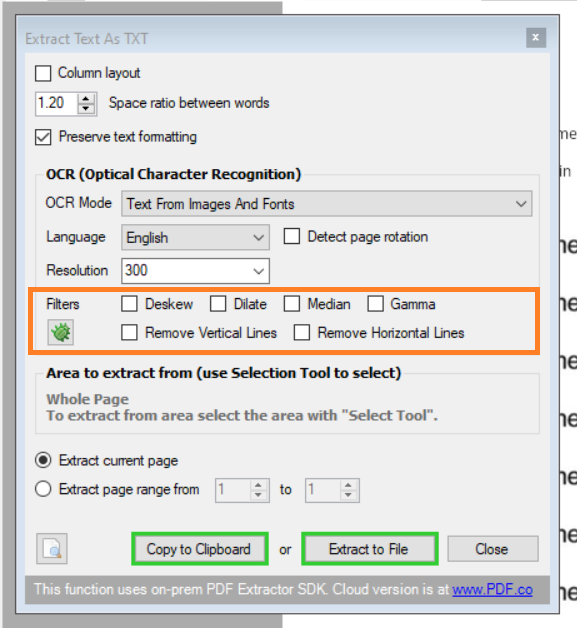
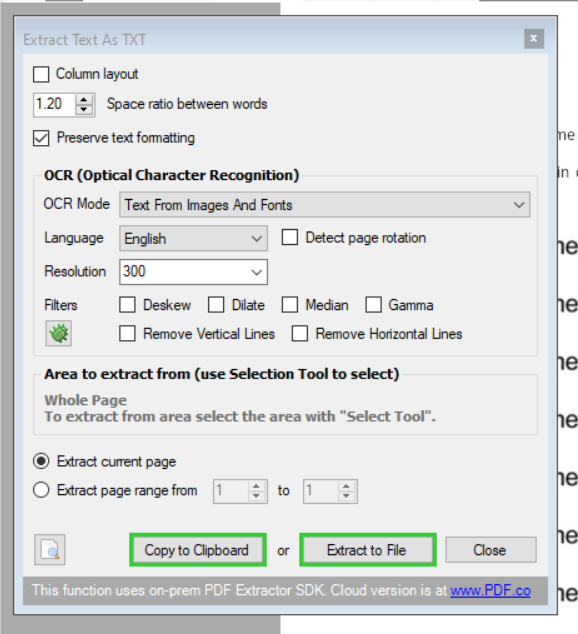
8. Choose Filter
The PDF Multitool also supports filters for image processing. We will not use any of the filters. Below is the description for each filter:
Deskew – straightens a crooked image.
Dilate – cures broken letters.
Median – removes noise.
Gamma – deals with blurred letters.
Remove Vertical Lines – removing vertical lines helps to avoid segmentation errors of the OCR engine.
Remove Horizontal Lines – removes unnecessary horizontal lines and also helps avoid segmentation errors of the OCR engine.
9. Extract the Scanned PDF File
We are now ready to extract the scanned PDF file. Click on the Extract to File button and save the extracted file in your local machine.
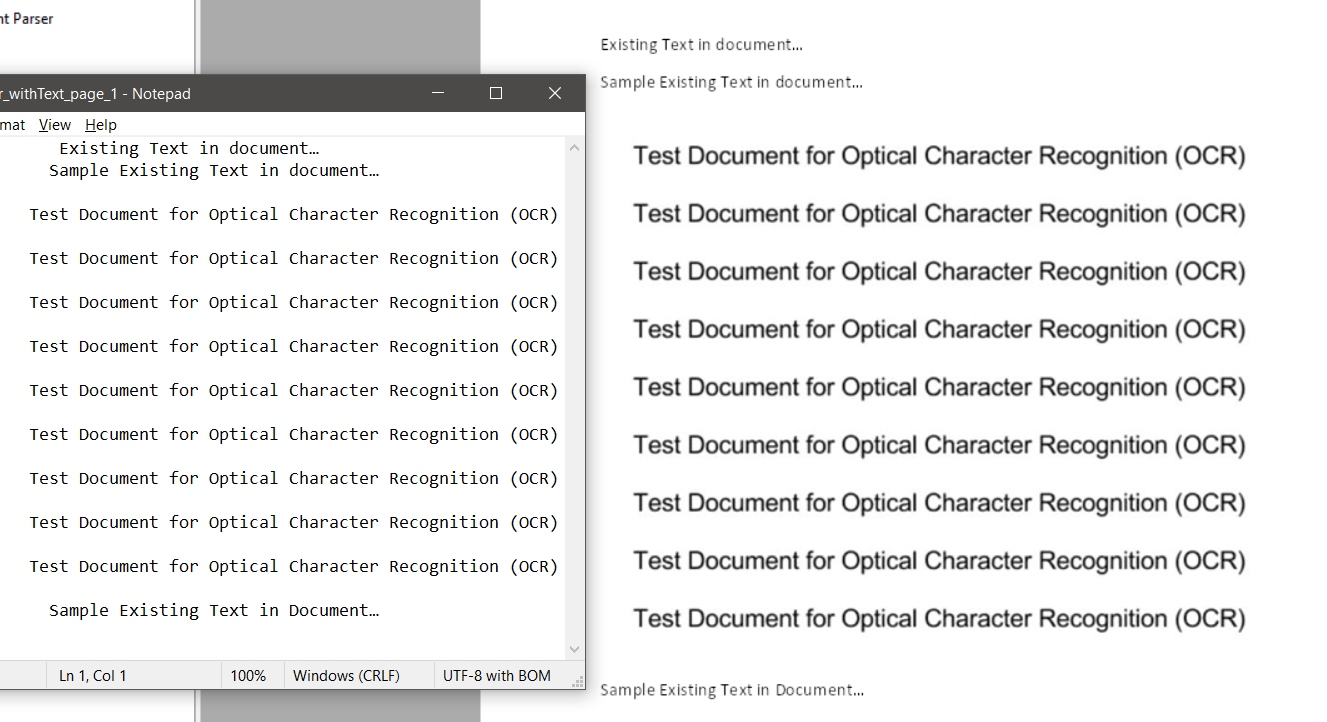
Great! We have successfully extracted the scanned PDF file and converted it to text.
In this tutorial, we have learned how to identify a searchable and non-searchable PDF document. We used the different toggle options to see the different objects in the PDF file. We reviewed the different OCR Modes, supported languages, and filters. And most of all, we learned how to extract a scanned PDF into text.
Screenshot of Source File and Output File Side by Side