Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
In many cases, it is beneficial to be able to extract HTML from a PDF file. Doing this makes the entire process of generating an HTML document easy and straightforward. To make this extraction possible, the PDF Multitool application can be used. This tool is an excellent application for the extraction of HTML from PDF files and other documents. Beyond the extraction process of HTML, this tool can be used for a wide range of processes, conversions, and much more. Also, it is available for both free and commercial use.
HTML is defined as HyperText Markup Language. It is the typical markup language used to create documents that are usually displayed on all types of browsers. This type of language works very well with other tools to provide decent reading pages on the internet. Therefore, having the ability to convert any document into an HTML file is one of the most important processes that can be conducted.
The PDF – portable document format – is one of the most commonly used documents on and off the internet. Most people prefer to use PDF as it allows for the presentation of information as it would usually be viewed on a normal paper document. Additionally, this document is easy to create and use. Also, the PDF file can take in a lot of information in the form of text, images, videos, tables, and much more. Once a PDF file is created, it can be extracted into other forms of files and documents.
Using the PDF multitool is free for use for fair personal use. However, a user must pay a fee to use this application on a commercial basis. In addition, this tool allows for the processing of many other forms of documents from one form to another.
How to Extract HTML from PDF
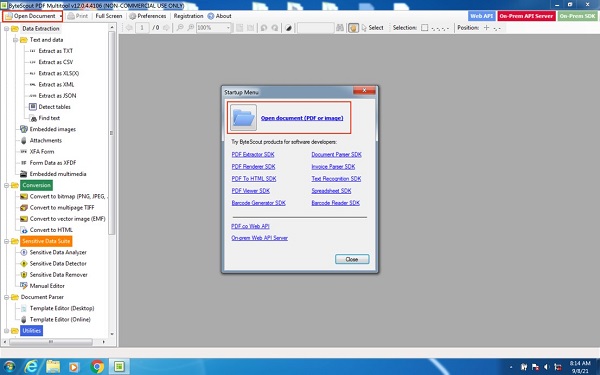
To get started with the extraction process of HTML from PDF, a user must launch the PDF Multitool application. Once opened, a pop-up opens, and the snapshot of the software is shown below.
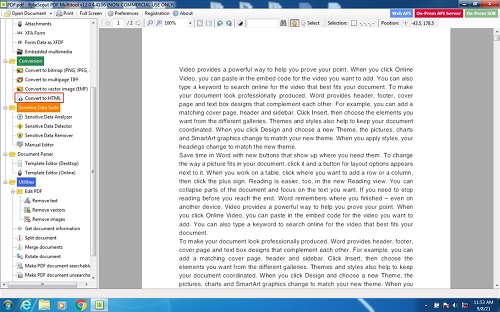
From the image above, a user can upload a PDF file using two options. These two options are highlighted in red. Once the PDF file is uploaded, it appears on the control panel of the application as seen below.
Choose Your Options for Extraction
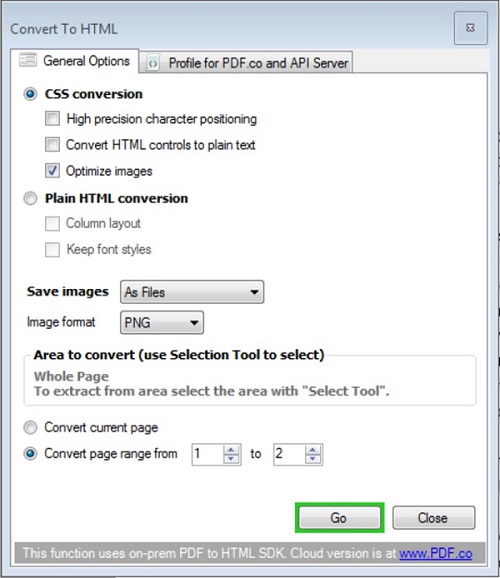
From the image above, you can see the document. Also, you can see the option for extracting HTML from a PDF file highlighted in red. By clicking this option, another option opens up. The snapshot is shown below.
From the image above, a user has several options to select from. A user is able to extract HTML from PDF either by CSS conversion or plain HTML conversion. By clicking the go option, the process of extraction begins.
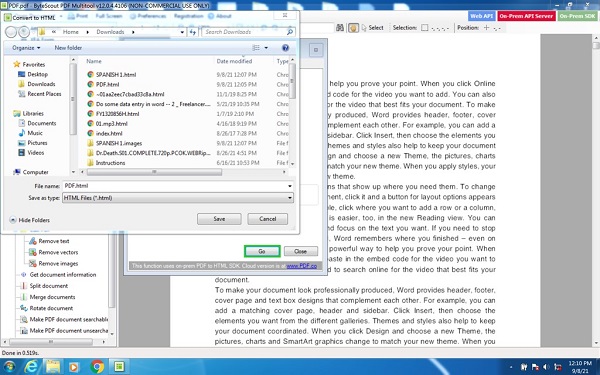
Clicking on the save option stores the HTML document on the file. Opening the newly converted document opens it as an HTML file.