Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to Extract PDF Information and Convert into Google Sheets
How to Extract PDF Information and Convert into Google Sheets
PDF is an application utilized for communicating comprehensive information from one system to another. This electronic format allows the users in obtaining large data over various platforms efficiently and quickly. The PDF file format is free from the computer operating system.
This quality makes the PDF file format portable and cooperative on any system. It can include hyperlinks, text, and much more. Hence, PDF is extensively utilized by users all over the world.
Users face problems when they want to extract some important information from PDFs into google sheets. It is not an easy task to extract data correctly from PDFs.
For example, some businesses require daily reports. Sometimes it is difficult for users to extract important information such as tables, images. This post is going to explain how to extract PDF information and convert it into Google Sheets and how to convert different file formats to excel. Let’s take a look at it in more detail.
How to Extract PDF information?
The ByteScout PDF Extractor SDK enables developers to transform PDF to text, obtain images from PDF, transform PDF to CSV for Excel, PDF to XML. The great thing about this tool is that it works without any extra software needed. You can also find a particular text from the uploaded PDF. For this, just upload your PDF and click on the “Find Text” option in the left pane. The “Find What” window will appear and here you can find the required text by entering it in the box.
Here we are going to extract PDF data. Now, Click on the link of PDF Extractor SDK and install it on your computer. It will take exactly 2-3 minutes to install it on your computer. The UI also allows the conversion of PDF to Excel, PDF to CSV, and PDF to XML.
You can also extract embedded images, tables, attachments, XFA forms, and embedded multimedia and Form data as XFDF and PDF metadata. It is simple to obtain tables from PDF using PDF Extractor SDK with the automatic table detector. Tables can be automatically picked and derived as CSV, XML, or JSON data.
The data extraction has a total of five extraction components. These are as follows:
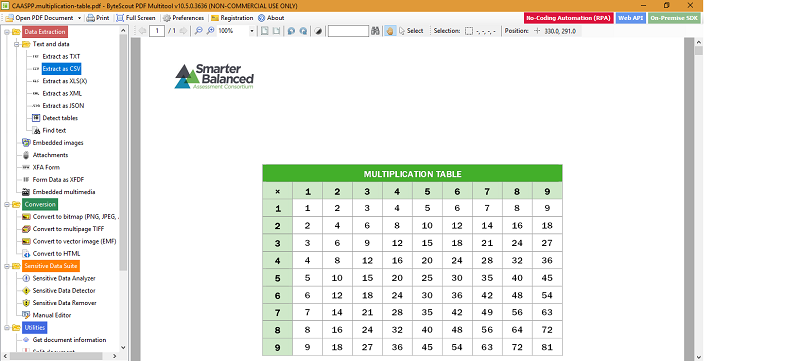
Now, if you want to extract the text from the PDF then just click on the “Open PDF Document” option on the upper left corner of the UI. Now, select the PDF saved on your computer from which you want to extract data. The following image is displaying the sample uploaded PDF.
Here we have used a sample PDF from which we will extract data as CSV. The PDF file contains some mathematical equations and mathematical tables. By using PDF extractor utilities we will extract data from the PDF.
Now, click on the “Extract as CSV” option in the Sidebar and save this file on your computer or a Google drive. In this way, you can extract data from PDF files on a Sheet or a word file. SDK will extract plain text from PDF files regardless of encoding.
It also converts PDF to Excel, PDF To CSV, PDF To XML. It can also extract and convert tables to CSV that can be easily transformed into MS Excel format. Now let’s take a look at how to convert different file formats to excel.
How to convert the different file formats to Excel?
Now, Excel is one of the most important tools for users. Excel is one of the most significant because of the important role it performs in many areas. It is the most utilized spreadsheet program in many marketing activities, classwork, and even personal data aggregation.
Excel is frequently utilized in accounting and finance because of its capacity to automate computations and its provision for multiple formulas.
Now, if you want to convert different file formats to excel then the ByteScout PDF Extractor SDK can convert the different file formats to Excel. The following is a sample screenshot of the UI which is displaying the dashboard of PDF Extractor SDK. On the left-hand bar, the Dashboard contains various utilities of C# and VB.NET.
Now, if you want to convert an XML file to Excel then the first step is to upload your XML file by clicking on the Open tab present in the upper left corner of the UI.
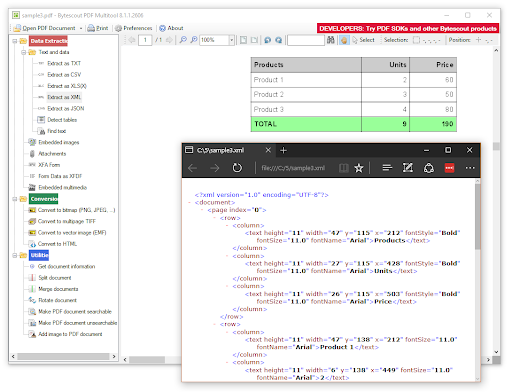
Now, click on the data extract option and then there are five options. The uploaded file is the XML file and we want to convert it into excel. To achieve this, click the “Extract as XML” option and the data will be displayed in a tabular format as displayed above. In this way, you can convert any file format to excel.
There are many options available here that help users to convert and extract tables into CSV and XML, regular expression search, working with broken texts, PDF documents merge and split as well as other things. The above image is displaying the extracted data and a file that we converted into Excel. Now, just save this file, and you are done.
No matter how complicated your PDF document’s formation is, you’ll notice that PDF Extractor is simple to apply and combine into your current systems seamlessly. PDF Extractor can even process broken files that have a complicated structure and would otherwise require to be processed manually.
PDF Extractor SDK is a completely functional set that incorporates functions to extract text, images, tables, text from images, raw images, forms, and field data. It has extensive documentation and tutorial set to make it simple for you to extract text from PDF with .NET.
The ByteScout PDF Extractor SDK is also built to work on PDF tables and PDF data extraction from unorganized documents like PDF, tiff, scans, images, and electronic forms. You can also convert PDF to CSV using ByteScout PDF Extractor SDK.
The library includes OCR, computer vision, and AI to give unparalleled functioning like table discovery, intuitive table formation extraction, data recovery, data rebuilding. The library also Supports PDF, TIFF, PNG, JPG images as data and can give CSV, XML, JSON formatted data.
For example, it also includes a complete collection of utilities like PDF splitter, PDF merger, searchable PDF maker. It can convert PDF to XML in VBScript and many other such things. The following example is displaying how to convert PDF to XML. The following image is displaying the UI.
Now, if you want to convert the PDF file to XML then just click on the “Open PDF Document” option on the upper left corner of the UI. Now, select the PDF saved on your computer which you want to convert to XML. Now, click on the “Extract as XML” option in the Sidebar and save this file on your computer or a Google drive. In this way, you can extract data from PDF files on a Sheet or a word file.
SDK will extract plain text from PDF files regardless of encoding. Bytescout also has PDF SDK for .NET, ASP.NET, ActiveX. It gives functionality to create rich PDF documents, complete API to create PDF Files. It can also use existing PDF files to insert the content and save back, extract images from PDF, extract data about PDF documents, and many other such crucial things.
It also contains the Document Parser. It is the accomplished document parsing engine that allows users to perform specific and simple to manage data extraction data from PDF invoices, records, and many such things. The good thing about this is that no programming is needed to build and manage data extraction templates! It also supports both local and scanned PDF files, PNG, JPG as well as English, German, French, Spanish, and many other languages.
It also has a BarCode SDK. It is the 1D and 2D barcode generator for various applications. The scanner investigates the barcode and writes the data collected in it into a database. It also allows users to configure the display of any barcode type that they want to create. It enables users to maintain the end product. The good thing about this barcode generator is that it implicitly creates into a computer system and this remarkably reduces the time it takes to process such data and decreases the potential human data error.
How To extract data such as images from PDF?
The above software can also be used to extract data like images from the PDF file and then it can be converted to Google sheets. The Bytescout multitool can implement these characteristics. PDF data extractor is available as a feature of PDF Extractor software. PDF is an integral part of today’s computer world.
Sometimes users want a quick and reliable method to convert their PDF files to XLS or XLSX file format. This is because of a test job from a customer. This tool can be one efficient tool for completing such tasks too.
Suppose you need page content as plain text or pictures then such data can be obtained. For instance, the following image is showing how to obtain data from PDF. To accomplish this, the first step is to install a multitool. Next, click on PDF Multitool. The following image will be presented.
The next step is to click the “Open PDF Document” option. This option is on the upper left corner of the tool user interface. Now, choose the PDF stored on your machine. You will pick the PDF file from which you want to extract data. The following image is presenting the sample uploaded PDF.
To accomplish this, select the “Open PDF Document” and then go to the “conversion” option and then choose “Convert to Bitmap(PNG, JPEG). With the help of this tool, users can efficiently capture the images from the PDF file. Now, the steps mentioned in the first section can be used to convert the data from the PDF and then convert it to google doc.
You usually obtain PDF files with exceptional pictures, which you may need to derive and share. Furthermore, you may also need to maintain possession of those pictures, or even stop third parties from using them before you issue them. We recommend this tool for personal use. It can be upgraded anytime for business use.
There are many options available in the ByteScout tool. For example, this tool also supports users to alter, convert and obtain tables into CSV and XML. It also allows regular expression research, handling broken texts, and then PDF documents merge and split. The only important thing users have to follow is that they simply have to click the correct option and then save the file and they are done. As mentioned, this utility tool can perform various tasks.
All of the APIs involved are readily accessible and optimized to developers with any stage of expertise and awareness about electronic documents. You can examine the Trial version to obtain data from PDF with C#, the extraction method is simple and interesting.
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
LiceCap is a very useful tool to create GIF images from screen recording. It's open-source and much popular among developer communities. The final GIF image...
There are various automation tools available to automate the application but very few for the desktop application. If you google then you will find a...