Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
This article aims to show how to extract data from PDF files including text, image, audio, video using C#. We all know that PDF format became the standard format of document exchanges and PDF documents are suitable for reliable viewing and printing of business documents. Almost all office software like Microsoft Office, LibreOffice, or OpenOffice.org had integrated the PDF format into them and they all had implemented the very useful feature known as “Export to PDF”. So exporting to a pdf file is now very easy, but what about the inverse process?
Let’s consider that you’ve received a document in PDF format and want to extract some information from it. At first glance, the task seems to be quite easy with just copying from the document source and pasting it somewhere else. But thing becomes complicated when you’re dealing with a lot of data, this tremendous process will make your work life awful. Facing that it’s appropriate to use dedicated tools or specialized frameworks to automate the whole of the job. Not only they will improve your productivity but also save you time. This article has three main sections:
How to Extract table from PDF with Adobe Acrobat Pro DC
As its name implies, Adobe Acrobat is a commercial app made by Adobe and it is the first and the official software to work with PDF files. You can download the 7 days trial version at https://acrobat.adobe.com/us/en/free-trial-download.html. At the time of writing, the released version is Adobe Acrobat Pro DC 2015 Release.
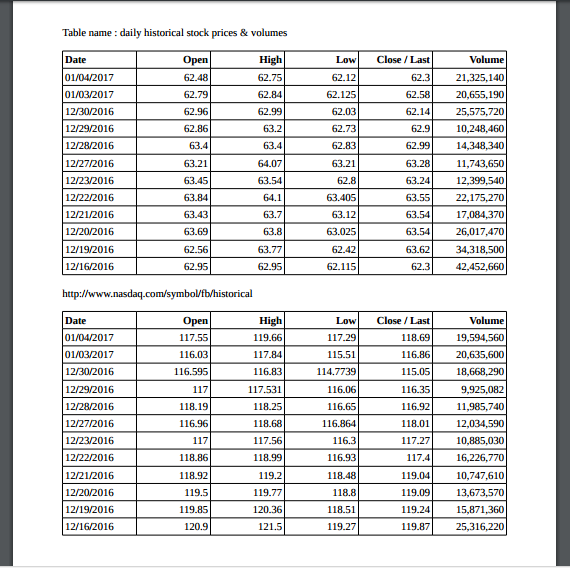
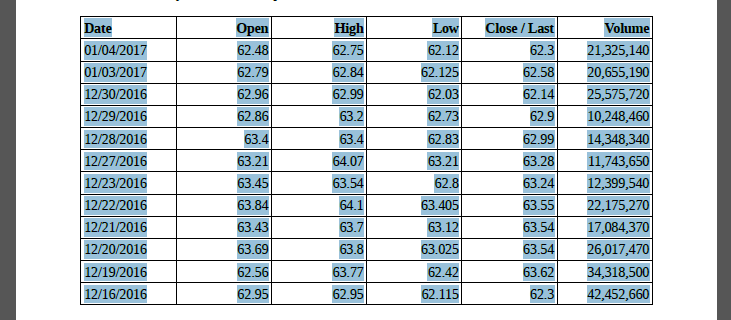
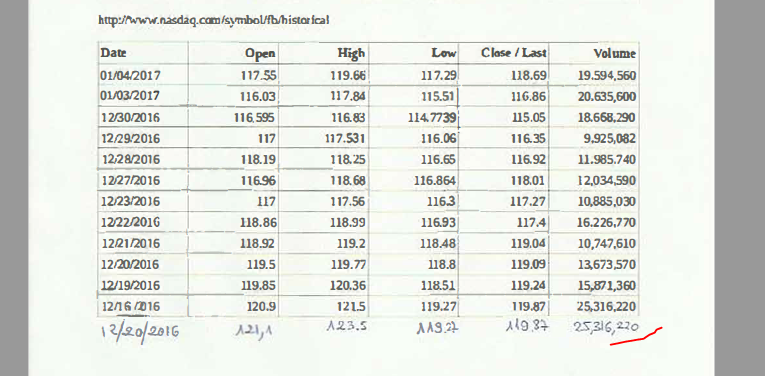
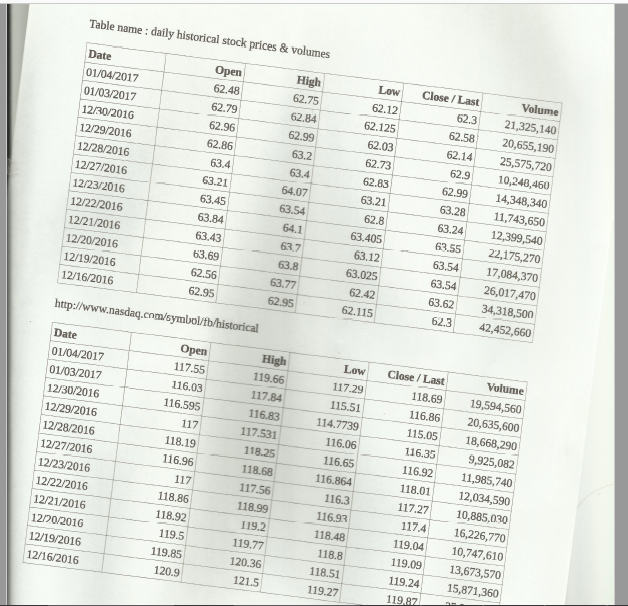
You also have to download our case study files here (sample1). Its content looks like below:
The table contains daily historical Microsoft and Facebook stock prices and volumes from the Nasdaq public website.
We need to manually extract the table’s content and export it to different formats like CSV, TXT,…
Step 1: Open the PDF file
In Adobe Acrobat Pro DC > File > Open
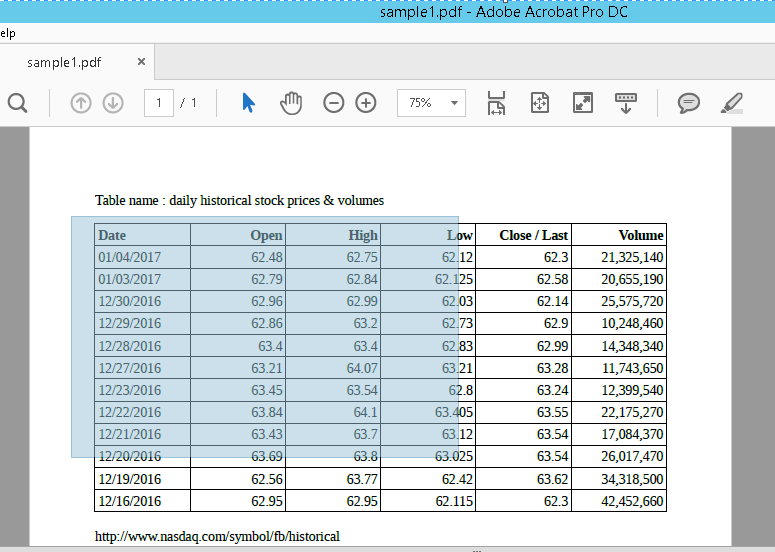
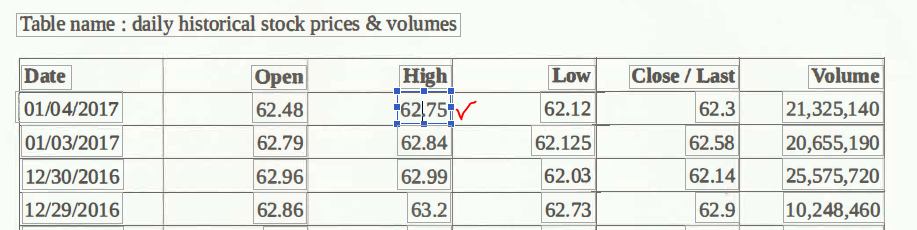
Step 2: Locate the table from which you want to extract data and drag a selection over the table as shown below
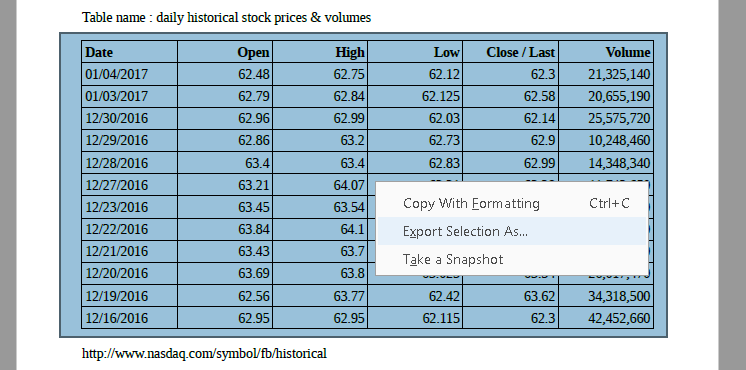
Step 3: Right-click and select “Export Selection As…”
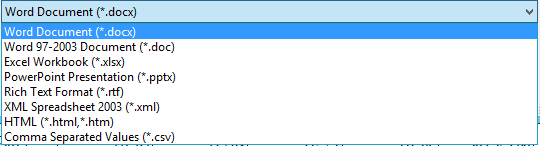
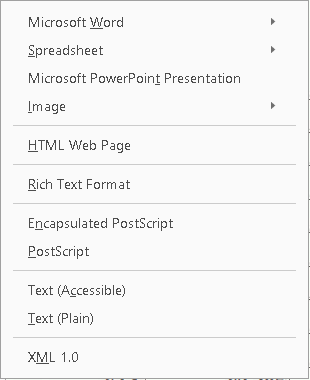
Step 4: Choose the export type
Adobe Acrobat Pro DC can handle up to 8 different formats:
Adobe Acrobat Pro is the most powerful tool to manipulate PDF files. In a few words, you can do whatever you want with your pdf file with it – except for some limitations that we’re going to see in section 4 (dealing with rich media content).
Extract data manually with Adobe Reader
Adobe Reader PC is a simple software to read PDF files. It has some limitations compared to its counterpart Adobe Acrobat Pro. However, you can do some basic stuff like copying the table’s contents and pasting it into your favorite spreadsheet app.
Step 1: Open the file with Adobe Reader
Step 2: Select the table’s content by dragging any desired rows and columns
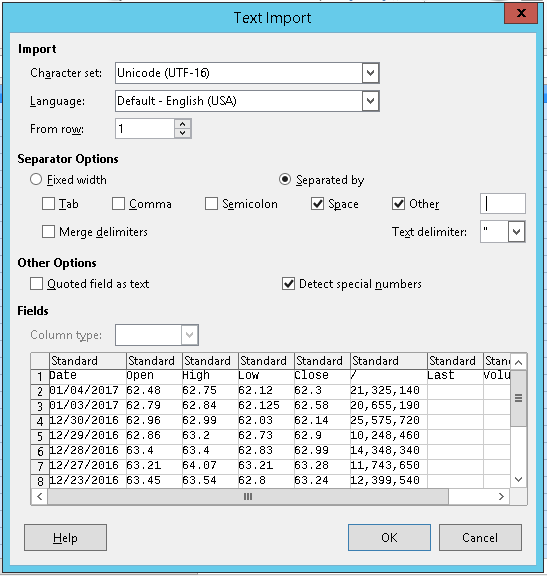
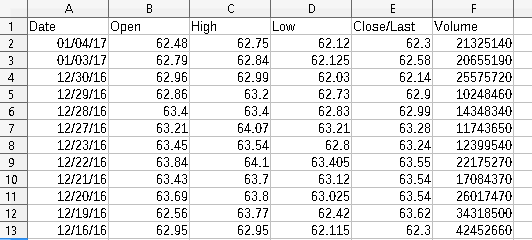
Step 3: Open your favorite spreadsheet app and paste the selection into it, we’re using LibreOffice Calc in this article
As seen in the figure below, we have to define a column delimiter in order to correctly display the content.
Step 4: Click OK
Using our spreadsheet software, we can then export to many other formats. In our case, LibreOffice gives us 15 available formats.
Abode Reader is not as flexible as Adobe Acrobat Pro, it hasn’t actually any export features. Its main utility is to visualize, print, and fill out PDF documents.
The two previous sections show you two ways to manually extract data from tables. They both are working well and are very useful for small loads. The next section will show you how to extract data from PDF tables using programming tools. We will focus essentially on PDF Extractor SDK.
PDF Extractor SDK (https://bytescout.com/products/developer/pdfextractorsdk/index.html) is one of Bytescout’s products. It allows developers to convert/extract data from PDF and export them to other formats. This is important to know that we can do that without any additional software required, unlike the actual Adobe SDK which mandatory needs Adobe Acrobat software to be installed.
After installing PDF Extractor SDK, all requisites dll can be found in the folder C:\Program Files\Bytescout PDF Extractor SDK
.NET Compatibility
PDF Extractor SDK supports the following .NET Frameworks:
You then need to do “add a reference” to the Bytescout.PDFExtractor.dll library.
PDF Extractor SDK, how does it work?
So, let’s see how to extract tables from PDF with this tool. Prior to any data extraction processes, we need to locate the targeted table among all the tables in the PDF document. This task is done by the Bytescout.PDFExtractor.TableDetector object which can loop over existing tables in the document.
The program below shows how to locate the N-th table (targetTableNumber variable) in the P-th page (targetPageNumber variable) of the whole PDF document.
using Bytescout.PDFExtractor;
namespace Topic4.Sample1.TableDetectorSample
{
class Program
{
static void Main(string[] args)
{
//The path of the PDF file
var pdfFile = @"sample1.pdf";
// this is the index of the page containing the targeted table
int targetPageNumber = 1;
// this is the value of the table we are looking for, 1 or 2 in the current example
int targetTableNumber = 1;
// Create an instance of a TableDetector
TableDetector tdetector = new TableDetector();
// License informations here
tdetector.RegistrationKey = "demo";
tdetector.RegistrationName = "demo";
// Load the document file
tdetector.LoadDocumentFromFile(pdfFile);
// Count the number of pages in the actual PDF file
int pageCount = tdetector.GetPageCount();
// Loop over document pages ...
for (int i = 0; i< pageCount; i++)
{
//... we are only interested in the targetPageNumber-th page
if (targetPageNumber != (i + 1)) continue;
//... if tables are found in the current page...
if (tdetector.FindTable(i))
{
int tableLoopNumber = 1;
//... loop over the tables in the current page ...
do
{
if (tableLoopNumber == (targetTableNumber-1))
{
//... targetTableNumber-th table in the targetPageNumber-th page is here
break;
}
tableLoopNumber++;
}
while (tdetector.FindNextTable());
}
}
}
}
}
Filters:
The TableDetector class offers some useful properties to filter the search:
DetectionMinNumberOfColumns
DetectionMinNumberOfRows
After locating the right table, we want to gather some data from it. This is achieved by an instance of extractor class: CSVExtractor, TextExtractor, JSONExtractor, XLSExctrator,… In the same method explained above, you can extract data from PDF tables using VB.NET. For this, after installing PDF Extractor SDK, all the required DLL are already in the folder C:\Program Files\Bytescout PDF Extractor SDK. As mentioned earlier, the PDF Extractor SDK supports various .NET frameworks such as .NET Framework 2.0, .NET Framework 3.5 / .NET Framework 3.5 Client Profile and .NET Framework 4.0 / .NET Framework 4.0 Client Profile.
Just as executed above here also you will do “add a reference” to Bytescout.PDFExtractor.dll library. After this, locate the targeted table among all the tables in the PDF document that you want to extract. This job is executed by the PDFExtractor.TableDetector object. The tabledetector object simply loops over the current tables in the PDF. Now, After finding the right table, you can gather your data from it. This is also executed by an instance of extractor class such as CSVExtractor, TextExtractor, JSONExtractor, XLSExctrator.
Export PDF table to CSV format with C#
We need to export the first PDF table of our case study document to CSV format. The previous program is updated as following
using Bytescout.PDFExtractor;
namespace Topic4.Sample1.TableDetectorSample
{
class Program
{
static void Main(string[] args)
{
//The path of the PDF file
var pdfFile = @"sample1.pdf";
// this is the index of the page containing the targeted table
int targetPageNumber = 1;
// this is the value of the table we are looking for, 1 or 2 in the current example
int targetTableNumber = 1;
//Create an instance of a TableDetector
TableDetector tdetector = new TableDetector();
//License informations here
tdetector.RegistrationKey = "demo";
tdetector.RegistrationName = "demo";
//Add some filters. Only tables meeting those criterias are considered
tdetector.DetectionMinNumberOfColumns = 1;
tdetector.DetectionMinNumberOfRows = 10;
//Load the document file
tdetector.LoadDocumentFromFile(pdfFile);
//Count the number of pages in the actual PDF file
int pageCount = tdetector.GetPageCount();
//Loop over document pages ...
for (int i = 0; i< pageCount; i++)
{
//... we are only interested in the targetPageNumber-th page
if (targetPageNumber != (i + 1)) continue;
//... if tables are found in the current page...
if (tdetector.FindTable(i))
{
int tableLoopNumber = 0;
//... loop over the tables in the current page ...
do
{
if (tableLoopNumber == (targetTableNumber-1))
{
//Process the targetTableNumber-th table in the targetPageNumber-th page
//Create the csv extractor object, set license information
CSVExtractor extractor = new CSVExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
//set the csv separator symbol - default value is comma
extractor.CSVSeparatorSymbol = ";";
//Load the pdf file into the extractor object
extractor.LoadDocumentFromFile(pdfFile);
// set extraction area for CSV extractor to rectangle given by table detector
extractor.SetExtractionArea(
tdetector.GetFoundTableRectangle_Left(),
tdetector.GetFoundTableRectangle_Top(),
tdetector.GetFoundTableRectangle_Width(),
tdetector.GetFoundTableRectangle_Height()
);
//Three methods to extract the table's content as csv
//returns a string using GetCSV method
string result_csv1 = extractor.GetCSV();
//returns a string using GetCSVFromPage method, page index is given as input parameter
string result_csv2 = extractor.GetCSVFromPage(targetPageNumber - 1);
// or directly save to the file system
extractor.SavePageCSVToFile(tableLoopNumber, "page-" + targetPageNumber + "-table-" + targetTableNumber + ".csv");
break;
}
tableLoopNumber++;
}
while (tdetector.FindNextTable());
}
}
}
}
}
Once the table is located, we create an extractor object to define the area inside which we want to extract data and the final CSV looks like
The next program shows how to extract a specific column from a given table.
The class Bytescout.PDFExtractor.TextExtractor is used to locate a specific text pattern in the PDF document. Then we define the extraction area and finally save the column content in a text file.
Bytescout.PDFExtractor.TextExtractorclass is not only limited to PDF files, but it can also locate and extract text from PNG, JPEC, BMP, TIFF files.
We also need to add the System. Drawing (because we’re using the RectangleF class) assembly for our project.
using Bytescout.PDFExtractor;
using System.Drawing;
namespace Topic4.Sample1.TextExtractorSample
{
class Program
{
static void Main(string[] args)
{
//The path of the PDF file
var pdffile = "sample1.pdf";
// this is the index of the page containing the targeted table
int targetPageNumber = 1;
// this is the value of the table we are looking for, 1 or 2 in the current example
int targetTableNumber = 1;
//Create an instance of a TableDetector
TableDetector tdetector = new TableDetector();
//License informations here
tdetector.RegistrationKey = "demo";
tdetector.RegistrationName = "demo";
//Add some filters. Only tables meeting those criterias are considered
tdetector.DetectionMinNumberOfColumns = 1;
tdetector.DetectionMinNumberOfRows = 10;
//Load the document file
tdetector.LoadDocumentFromFile(pdfFile);
//Count the number of pages in the actual PDF file
int pageCount = tdetector.GetPageCount();
//Loop over document pages ...
for (int i = 0; i < pageCount; i++)
{
//... we are only interested in the targetPageNumber-th page
if (targetPageNumber != (i + 1)) continue;
//... if tables are found in the current page...
if (tdetector.FindTable(i))
{
int tableLoopNumber = 0;
//... loop over the tables in the current page ...
do
{
if (tableLoopNumber == (targetTableNumber - 1))
{
//use a text extractor in order to extract text from the pdf document
TextExtractor extractor = new TextExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile(pdfFile);
// set to extract text column by column
extractor.ExtractColumnByColumn = true;
//Try to locate the "Close / Last" column header in the current page
bool close_last_header_found = extractor.Find(targetPageNumber - 1, "Close / Lasts", true);
//if found
if (close_last_header_found)
{
// Retrieve the boundary of the text
RectangleF rectangle = extractor.FoundText.Bounds;
//Set the selection area of the extractor
extractor.SetExtractionArea(
rectangle.Left
, rectangle.Top
, rectangle.Width
, rectangle.Height * 20
);
//Save to file
extractor.SaveTextToFile("output.txt");
//Dispose
extractor.Dispose();
}
break;
}
tableLoopNumber++;
}
while (tdetector.FindNextTable());
}
}
}
}
}
The content of the result file looks like this:
Close / Last
62.3
62.58
62.14
62.9
62.99
63.28
63.24
63.55
63.54
63.54
63.62
62.3
More generally, the class Bytescout.PDFExtractor.TextExtractor uses a rectangle surface called the extraction area. The extraction area is well defined by using four parameters:
the left and top coordinates are used to locate the top-left corner of the extraction area
the width is used to set the width of the extraction area
the height parameter specifies the height of the extraction area
Only texts standing inside the extraction area are going to be gathered during the extraction phase.
Parsing PDF table cell by cell with C# PDF API
With PDF Extractor SDK, we can navigate through the table’s cells using the Bytescout.PDFExtractor.StructuredExtractor class in the way of enumerating a matrix structure. The following program shows how to do that
using Bytescout.PDFExtractor;
using System;
namespace Topic4.Sample1.TableStructureSample
{
class Program
{
static void Main(string[] args)
{
//The path of the PDF file
var pdfFile = "sample1.pdf";
// this is the index of the page containing the targeted table
int targetPageNumber = 1;
// Create Bytescout.PDFExtractor.StructuredExtractor instance (former TableExtractor)
StructuredExtractor extractor = new StructuredExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile(pdfFile);
//Define the extraction area
extractor.SetExtractionArea(new System.Drawing.RectangleF(20,380,600,200));
for (int ipage = 0; ipage <extractor.GetPageCount(); ipage++)
{
//In the current program, we only need the first page
if ((ipage + 1) != targetPageNumber) continue;
//Prepare the page structure
extractor.PrepareStructure(ipage);
//Count the actual table rows
int rowCount = extractor.GetRowCount(ipage);
int CellsAlreadyScanned = 0;
//Loop over the row count...
for (int row = 0; row < rowCount; row++)
{
// ...then loop over the column
int columnCount = extractor.GetColumnCount(ipage, row);
for (int col = 0; col< columnCount; col++)
{
//The text of the table cell[row,col]
var cellValue = extractor.GetCellValue(ipage, row, col);
Console.Write(string.Format("{0}\t", cellValue));
}
Console.WriteLine("\n");
CellsAlreadyScanned += columnCount;
}
}
Console.WriteLine("Press any key..");
Console.ReadKey();
}
}
}
The program output is:
PDF table To JSON using C#
The following program shows how to extract data from PDF tables and save them as a JSON file using the Bytescout.PDFExtractor.JSONExtractor class. We can also retrieve some metadata (like font name, font size, font style, and position) information in addition to the actual cell content value.
using Bytescout.PDFExtractor;
namespace Topie4.Sample1.JsonExtractorSample
{
class Program
{
static void Main(string[] args)
{
//The path of the PDF file
var pdfFile = @"sample1.pdf";
// this is the index of the page containing the targeted table
int targetPageNumber = 1;
// this is the value of the table we are looking for, 1 or 2 in the current example
int targetTableNumber = 1;
//Create an instance of a TableDetector
TableDetector tdetector = new TableDetector();
//License informations here
tdetector.RegistrationKey = "demo";
tdetector.RegistrationName = "demo";
//Add some filters. Only tables meeting those criterias are considered
tdetector.DetectionMinNumberOfColumns = 1;
tdetector.DetectionMinNumberOfRows = 10;
//Load the document file
tdetector.LoadDocumentFromFile(pdfFile);
//Count the number of pages in the actual PDF file
int pageCount = tdetector.GetPageCount();
//Loop over document pages ...
for (int i = 0; i < pageCount; i++)
{
//... we are only interested in the targetPageNumber-th page
if (targetPageNumber != (i + 1)) continue;
//... if tables are found in the current page...
if (tdetector.FindTable(i))
{
int tableLoopNumber = 0;
//... loop over the tables in the current page ...
do
{
if (tableLoopNumber == (targetTableNumber - 1))
{
//Process the targetTableNumber-th table in the targetPageNumber-th page
//Create the csv extractor object, set license information
JSONExtractor extractor = new JSONExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
//Load the pdf file into the extractor object
extractor.LoadDocumentFromFile(pdfFile);
// set extraction area for CSV extractor to rectangle given by table detector
extractor.SetExtractionArea(
tdetector.GetFoundTableRectangle_Left(),
tdetector.GetFoundTableRectangle_Top(),
tdetector.GetFoundTableRectangle_Width(),
tdetector.GetFoundTableRectangle_Height()
);
// or directly save to the file system
extractor.SaveJSONToFile(tableLoopNumber, "page-" + targetPageNumber + "-table-" + targetTableNumber + ".json");
break;
}
tableLoopNumber++;
}
while (tdetector.FindNextTable());
}
}
}
}
}
Similarly, you can get a table from PDF using VBScript and save them as a JSON file using the Bytescout.PDFExtractor.JSONExtractor class. This tool also allows you to extract some metadata such as font name, font size, font style, and position. To accomplish this task, simply upload your file and the tool will automatically give you the JSON file. The following image is displaying the PDF table to the JSON file.
The ByteScout PDF extractor tool can also extract the entire files placed in the PDF. For example, in a supplement to including text and graphics, PDF files can include entire files inside them as attachments. This makes switching collections of documents more accessible and more secure. The ByteScout tool simply locates the file with Bytescout.PDFExtractor.AttachementExtractor.GetFileName with file’s index as an input parameter and then simply extract the file.
Convert PDF to JPG
In this section, you will learn how to convert PDF files to JPG using PDF.co Web API. WEB API is a more suitable alternative for more uncomplicated, lightweight services. It can handle any text format such as XML. WEB API can also be applied to build various REST Services.
The PDF is a simple program file. We are using the program file here, you can convert any PDF file to JPG using this tool. The PDF.co Web API includes a whole set of functions such as e-signature requests to data extraction, OCR, image recognition, pdf splitting. It can also produce barcodes and read barcodes from images, scans, and pdf.
Now, if you want to convert this PDF file into JPG then login to your PDF.co account > Go to Manual Tools. Here, you will find a list of tools such as PDF to CSV, PDF to XLS, and many more with the help of which you can convert your PDF files. In this section, we want to convert our PDF into JPG. So, select “PDF to JPG tool. Upload your PDF file and the tool will automatically convert your PDF to JPG. Once done, you can download your file. The following image is displaying the JPG file that has been converted from the PDF.
#Program to check if a number is prime or not
num=407
#To take input from the user
#num = int(input("Enter a number:"))
#prime numbers are greater than 1
if num > 1:
#check for factors
for i in range(2,num):
if (num % i) == 0:
print(num, "is not a prime number")
print(i, "times",num//i,"is",num)
break
else:
print(num,"is a prime number")
# if input number is less than
# or equal to 1, it is not prime
else:
print(num,"is not a prime number")
Extract PDF table to XML using C#
The same process as exporting to JSON applies here. Instead of using the JSONExtractor class, we have to use the XMLExtractor class. To save the XML into the file system we call the method XMLExtractor.SaveXMLToFile
Extract data from scanned documents / OCR
The rest of this article is about extracting data from scanned documents and OCR capabilities. We’ll see how to extract data with Adobe Acrobat DC and we’ll also see how to handle the data extraction process using C# and PDF Extractor SDK.
You can find below five scanned files that we’re going to use.
When we open the pdf scanned file with Adobe Acrobat DC, we see that it automatically tries to convert the page to editable contents. It pops out the message below
Once the pattern recognition is done each cell of our table becomes editable. More generally Adobe Acrobat DC has a powerful built-in OCR to automatically detect characters and texts inside the scanned page.
We can then export the modified document to many other formats.
Go to File > Export To >
You can download here the “Text (Plain)” version of our document
Extract data from a scanned document with poor quality of printing and handwriting note
The corresponding demo file is scan_sample1_70dpi_handwritingnote.pdf. The specificity of this file is that the scan is done at a low resolution of 70 dpi and having a handwriting note at the bottom of the table.
Despite the low accuracy of the OCR at 70 dpi, the major part of the data has been well reconstructed. However, it seems to have trouble detecting all cell borders, the result file is available here. The pattern recognition over the handwriting note had also failed.
The same process applied to the same document scanned at 600dpi is very accurate. The extraction process has performed well and all of the cells data are successfully gathered (here)
The file scan_sample1_600dpi_badqualityprinting.pdf (scan at 600 dpi with poor ink quality) had definitely failed through the extraction process. Adobe Acrobat DC didn’t recognize any patterns and had considered it as a blank page.
The last file we’re trying to extract is scan_sample1_600dpi_badorientation.pdf. The particularity of this file is bad orientation during the scan process.
However, Adobe Acrobat automatically adjusts the document page orientation during the pattern recognition process as seen in the figure below
The data extraction result is available here We can see that almost all of the data are well retrieved.
Extract data with OCR from scanned documents using C# and PDF Extractor SDK
The following program extracts data from the pdf document file scanned at 600dpi under normal conditions
using Bytescout.PDFExtractor;
namespace OCRExample
{
class Program
{
static void Main(string[] args)
{
var pdfFile = @"scan_sample1_600dpi_normal.pdf";
// Create Bytescout.PDFExtractor.TextExtractor instance
JSONExtractor extractor = new JSONExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
//Load the pdf document file
extractor.LoadDocumentFromFile(pdfFile);
//We are only interested in text
extractor.OCRMode = OCRMode.TextFromImagesAndFonts;
//Define the language data folder
extractor.OCRLanguageDataFolder = @"C:\\Program Files\\Bytescout PDF Extractor SDK\\net4.00\\tessdata\\";
//The actual language is eng for english
extractor.OCRLanguage = "eng";
//We set the resolution to 600dpi
extractor.OCRResolution = 600;
//Save the file
extractor.SaveJSONToFile("OCR_JSON_scan_sample1_600dpi_normal.json");
}
}
}
For each pattern, the OCR engine associates the property named @OCRConfidence which indicates how good or bad the recognition was, the higher the value more accurate is the result. The OCR engine also returns the predicted font name, the size, the coordinate of the data, its width and height in the PDF document, and the text value of course.
The OCR uses a set of language libraries (located at C:\\Program Files\\Bytescout PDF Extractor SDK\\net4.00\\tessdata\\ ), the default installation contains four languages: English, German, French, and Spanish. The property JSONExtractor. OCRLanguageDataFolder is set to the actual language of the document. The OCR process is active when the property JSONExtractor.OCRMode is different than OCRMode.Off. We can also apply multiple preprocessing algorithms to the OCRImagePreprocessingFilters property of the extractor object to help the OCR Engine to give better pattern recognition performance. We can mix between the following methods AddContrast(), AddDeskew(),AddDilate(), AddGammaCorrection(), AddHorizontalLinesRemover(), AddMedian(), AddVerticalLinesRemover(). According to the case, the time process may vary from a few seconds to one minute or even more per page.
Extract rich media contents
Extract rich media contents with Adobe Acrobat DC
In the Adobe Acrobat glossary, rich media are audio and video content. They can be a 3D animation, an audio file, a flash SWF animation, or a video file in H264 compliant format. At the time of writing, extracting rich media contents isn’t a supported feature, this is one of the major lacks of Adobe Acrobat and you should use third-party tools to do that. PDF Extractor SDK can, fortunately, do all the jobs for you just with only a few lines of code. This is exactly what we’ll show you in the next section.
Extract rich media contents from PDF with PDF Extractor SDK and C#
Pdf content is not only limited to text format. Most of the time PDF documents contain pictures or documents and even more complex objects like audio or video media files may be embedded into the document.
The following example shows you how to extract such objects using PDF Extractor SDK
The basic steps to perform this process are:
1- Create the extractor object. The type actually depends on what kind of objects we’re going to extract
2- Locate the object in the document. We can loop over existing objects to find the index of the targeted object.
3- Call the appropriate method of the extractor object in step 1 to extract the data. The extractor object has also some interesting properties about the data as file type, data size,
4- Save the extracted data to the file system.
For more details about supported rich media contents, please visit the official adobe acrobat help page https://helpx.adobe.com/acrobat/using/rich-media.html
Extract audio file mp3 from PDF document with PDF Extractor SDK and C#
The Bytescout.PDFExtractor.MultimediaExtractor is the most suitable component to extract an embedded audio file from a PDF document.
The file PDF_with_mp3.pdf contains an audio mp3 object. We can extract the audio file using the following lines of code
Note: The file extension was original “.mp3”, however the method MultimediaExtractor. GetCurrentAudioExtension() returns “.mpa” file extension.
Some interesting methods are MultimediaExtractor.GetCurrentAudioBytesSize() to get the actual file size, MultimediaExtractor.GetDocumentAudioCount() returns the number of embedded audio files in the document and MultimediaExtractor.GetNextAudio() allows switching to the next audio file.
Extract video file from PDF document with PDF Extractor SDK and C#
You can extract any embedded video files using the following steps.
1- Create an instance of Bytescout.PDFExtractor.MultimediaExtractor class to grab the video file
2- Save the file to disk using the method MultimediaExtractor.SaveCurrentVideoToFile.
The following program shows how to extract the embedded video file ( H264 compliant otherwise it will fail) in PDF_with_video.pdf and save it into the file system.
The method MultimediaExtractor.GetFirstVideo() is where we locate the targeted video. Some useful methods are:
– MultimediaExtractor.GetDocumentVideoCount() to get the total number of video objects in the current file.
– MultimediaExtract.GetNextVideo() to navigate to the next video file.
Extract images from PDF file using Adobe Acrobat DC
Adobe Acrobat DC can extract embedded images in the PDF document.
The following steps show you how to do that.
Step 1: Open the document in Adobe Acrobat DC
Step 2: Tools > Export PDF
Step 3: The last screen allows you to configure the image type
Extract images from PDF file using C#
PDF Extractor SDK can extract any embedded images in the pdf document. It has full support on Gif, Tiff, jpg… formats. You can achieve that in three steps:
1- Create an instance of Bytescout.PDFExtractor.ImageExtractor class
2- Load the PDF document with the method to Locate Bytescout.PDFExtractor.ImageExtractor .LoadDocumentFromFile
3- Locate the image on the page
4- Save the image with the method Bytescout.PDFExtractor.ImageExtractor.SaveCurrentImageToFile
Note: We need to use System.Drawing.Imaging assembly in order to use the ImageFormat class.
ImageExtractor extractor = new ImageExtractor();
extractor.LoadDocumentFromFile(@"Pdf_with_image.pdf");
var firstImageFound = extractor.GetFirstImage();
if (firstImageFound)
{
extractor.SaveCurrentImageToFile("firstimage.png", ImageFormat.Png);
}
One interesting feature is the ability to choose the export format regardless of the initial format of the image. Depending on your need, you can pass here PNG, JPEG, ICO, GIF, BMP, Exif they all are well handled by PDF Extractor SDK.
Extract embedded documents in PDF file
PDF Extractor can extract any embedded documents from pdf. This process involves four steps
1- Create an instance of Bytescout.PDFExtractor.AttachementExtractor class
2- Load the PDF file using Bytescout.PDFExtractor.AttachementExtractor.LoadDocumentFromFile method
3- Locate the file with Bytescout.PDFExtractor.AttachementExtractor.GetFileName with file’s index as an input parameter.
4- Call the Save method to write to disk.
AttachmentExtractor extractor = new AttachmentExtractor();
extractor.LoadDocumentFromFile(@"Pdf_with_files.pdf");
extractor.Save(0, extractor.GetFileName(0));
We’ve seen along with this article several ways to extract data from PDF documents. If you want to do it manually, Adobe Acrobat DC is definitely the best choice. However, this product is not free and you have to pay to get a commercial license. An alternative is to use Adobe Reader but there are some limitations to using it. For the automated extraction process, we’ve seen that PDF Extractor SDK is a simple, complete, and reliable tool for pdf extraction data. It supports a lot of commonly used formats (XML, CSV, JSON, HTML, text, and so on).
For more complex OCR tasks, Adobe Acrobat is a very reliable software, the pattern recognition error rate is quite low and it also supports many export formats. PDF Extractor SDK offers a powerful OCR engine, many features are available to developers to optimize the character recognition process. PDF Extractor SDK is definitely a well-placed tool when your business requires dealing with rich media content. We’ve seen so far that it has the full support of extracting audios, videos from any PDF files and is compatible with any CLR-compliant programming languages C# / VB.NET.
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
Successful programmers love reading different coding books. Reading is an essential part of the programmers’ life. Reading and practicing are two signs of an exceptional...