Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to Extract a Table in Original Format with PDF Extractor SDK
How to Extract a Table in Original Format with PDF Extractor SDK
In the field of data mining, the trickiest part is to automate the software to read tables. In normal extraction, it’s just paragraph or image, but when tables are involved one needs to be sure that they can relate data from rows to their respective columns. And complexity raises when the table is spanned across multiple pages.
ByteScout PDF Extractor SDK or PDF.co Web API is one of the best solutions available in the market for this task. SDK provides many functionalities, but extract table from pdf is one of its strong points. Once the table is extracted, SDK provides many ways to use them like:
Export data to JSON
Export data to XML
Export data to CSV
Export data to Excel
The awesome thing about PDF Extractor SDK is that it works flawlessly with OCR. Now imagine finding useful information and analyzing them from tons of scanned documents. If we go manually by having operators examining and analyzing each file, it becomes costly, prone to error, and time-consuming. On the other hand, we can easily develop a strong algorithm with the help of data extracted by ByteScout PDF Extractor SDK and have resulted in seconds.
These videos explain how to extract a table in the original format:
Let’s delve into technicalities. In this article, we’ll examine a few programs covering different scenarios.
Program to extract table from PDF document;
Program to extract table from PDF document and export as CSV, Excel, XML, or JSON document;
Program to extract table from OCR/Scanned PDF document.
By the end of this article, you will get a basic idea of how to use ByteScout PDF Extractor SDK to extract a table from a PDF or image document.
ByteScout PDF Extractor SDK features:
Works with the majority of languages, including C#, cURL, Java, JavaScript, PHP, PowerShell, VB.NET, etc. It also provides the PDF.co API version which itself can be used by most languages without installing ByteScout SDK.
Does NOT require any other application installed. (DOES NOT REQUIRE Adobe Reader or any other software)
Extracts tables from PDF as CSV or XML data from a whole page, a whole PDF document page, or from a given rectangle
Converts PDF to Text from a whole page, a whole document, or from a given rectangle.
Please note: in order to use any of the following programs you need to have ByteScout PDF Extractor SDK. One of the easy ways to have this library along with other ByteScout libraries is to install ByteScout SDK at your machine from this link.
Enough of talking, Show me the code!!!
* Program to extract table from PDF document
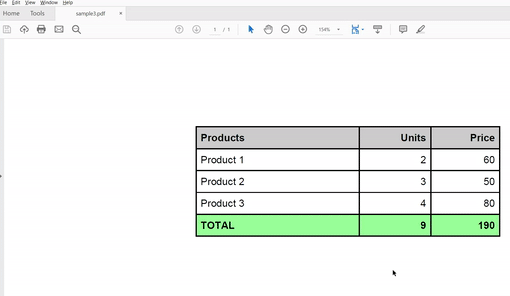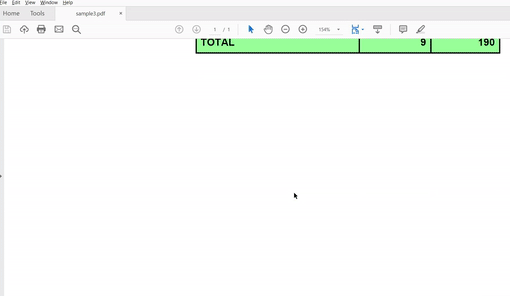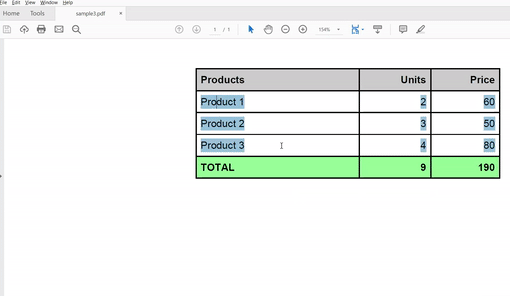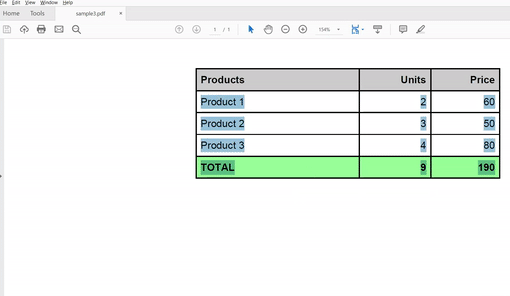
Here’s the input file used for this program.
The code is as follows:
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.StructuredExtractor instance
StructuredExtractor extractor = new StructuredExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile(@".\sample3.pdf");
for (int pageIndex = 0; pageIndex < extractor.GetPageCount(); pageIndex++)
{
Console.WriteLine("Starting extraction from page #" + pageIndex);
Console.WriteLine();
// Fetch all data for rows and columns
extractor.PrepareStructure(pageIndex);
// Write fetched data to console
int rowCount = extractor.GetRowCount(pageIndex);
for (int row = 0; row < rowCount; row++)
{
int columnCount = extractor.GetColumnCount(pageIndex, row);
for (int col = 0; col < columnCount; col++)
{
Console.WriteLine(extractor.GetCellValue(pageIndex, row, col));
}
}
}
// Cleanup
extractor.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key to exit..");
Console.ReadKey();
}
}
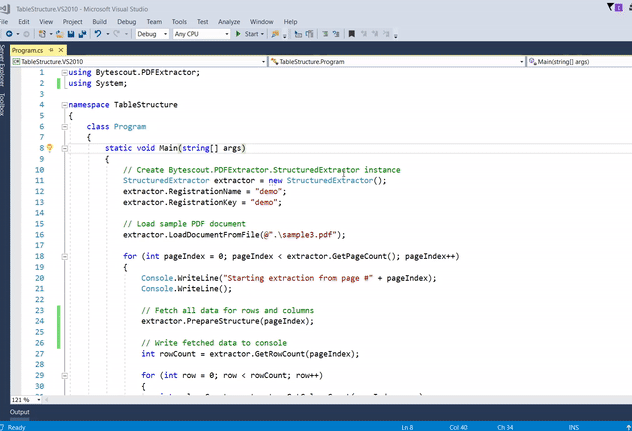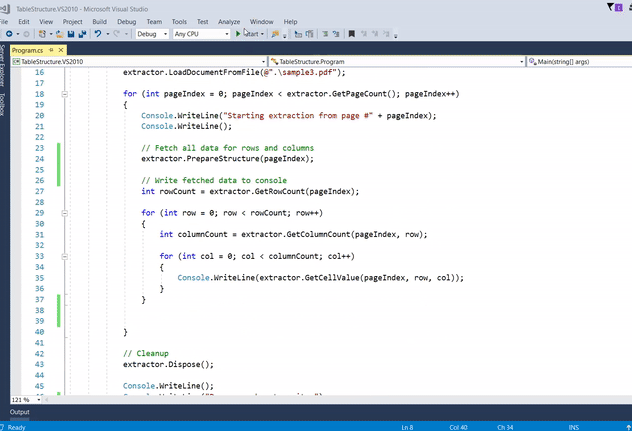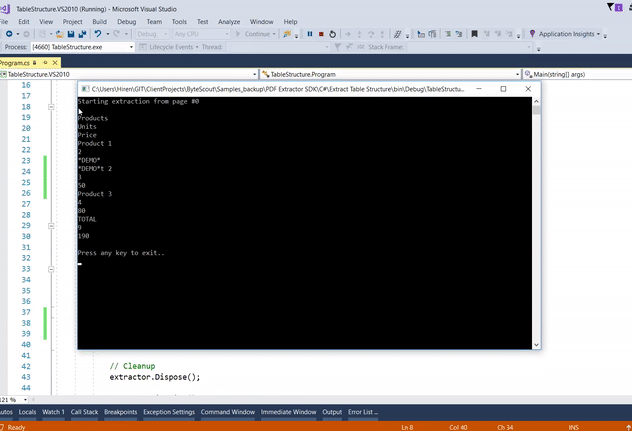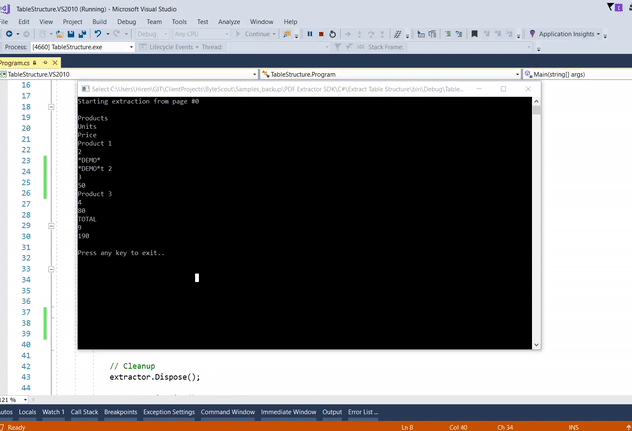
And here’s the output. We are not formatting an output, but it’s evident that it does the job.
Though the code is self-explanatory, let’s decode it.
StructuredExtractor extractor = new StructuredExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
Here, we are creating an extractor instance and providing the registration key and name. We used a specific StructuredExtractor here, as we want to inspect extracted data in each row and column. For this demo purpose, we are using test keys, however the same needs to be replaced with actual keys when in production. You’ll get these keys when you purchase the ByteScout SDK package.
Step-2: Provide input source
// Load sample PDF document
extractor.LoadDocumentFromFile(@".\sample3.pdf");
Here, we have provided an input document on which extraction needs to be performed. We have provided a file path here, though we can pass the input stream also by using the LoadDocumentFromStream method.
Step-3: Perform data extract
for (int pageIndex = 0; pageIndex < extractor.GetPageCount(); pageIndex++)
{
// Fetch all data for rows and columns
extractor.PrepareStructure(pageIndex);
…
The next step would be extracting data. Extractor first gets no of pages available and then finds/prepares table structure within that page.
Once this structure is available, we only need to utilize data as per our requirements. For instance, in this example, we have displayed data in the console.
That’s all. It’s this simple to utilize ByteScout PDF Extractor SDK to extract tables from PDF. In the next article, we’ll see how to export data to JSON/XML/CSV/Excel.
* Program to extract table from PDF document and export as CSV, Excel, XML, or JSON document
For this program, we have used the same input PDF.
The code is as follows:
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.CSVExtractor instance
CSVExtractor extractor = new CSVExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile("sample3.pdf");
// you can change CSV separator symbol (if needed) from "," symbol to another if needed for non-US locales
//extractor.CSVSeparatorSymbol = ",";
// Save extracted CSV data
extractor.SaveCSVToFile("output.csv");
// Cleanup
extractor.Dispose();
Console.WriteLine();
Console.WriteLine("Data has been extracted to 'output.csv' file.");
Console.WriteLine();
Console.WriteLine("Press any key to continue and open CSV in default CSV viewer (or Excel)...");
Console.ReadKey();
// Open result document in default associated application (for demo purpose)
ProcessStartInfo processStartInfo = new ProcessStartInfo("output.csv");
processStartInfo.UseShellExecute = true;
Process.Start(processStartInfo);
}
}
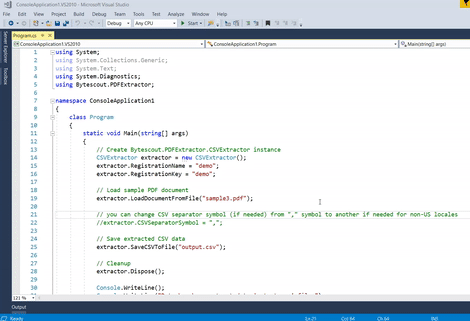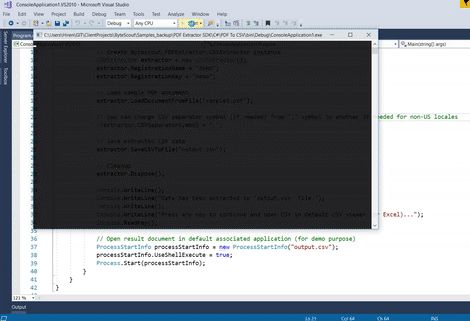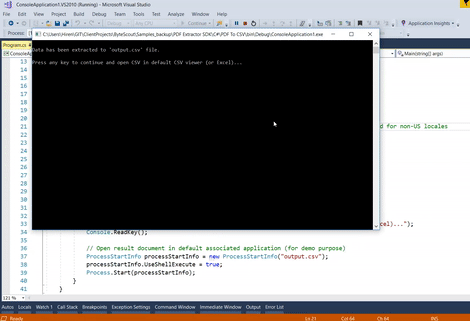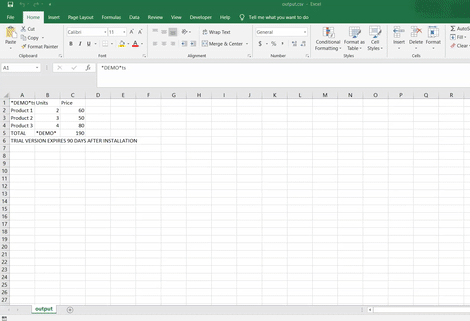
Please take a look at the output:
Let’s analyze. You can see the pattern here, initialize, set the source, and perform the task.
In this program, we are using the CSVExtractor instance of ByteScout.PDFExtractor library.
We are specifying source to physical file by invoking method LoadDocumentFromFile method, however, if we want to load a document from stream, we can use LoadDocumentFromStream
And now for the extraction and export part, we just need to call the method SaveCSVToFile; which export data to our specified file destination. Just like input, if we prefer to export as a stream, we can use the SaveCSVToStream method.
We can export data to other destinations like JSON, XML, EXCEL just like this; provided we use appropriate extractor instances as shown in the following summary.
Export To
Extractor Instance
Extract Methods
CSV
CSVExtractor
SaveCSVToFile, SaveCSVToStream
JSON
JSONExtractor
SaveJSONToFile, SaveJSONToStream
XML
XMLExtractor
SaveXMLToFile, SaveXMLToStream
Excel
XLSExtractor
SaveXLSToFile, SaveXLSToStream
* Program to extract table from OCR/Scanned PDF document
Let’s view the code.
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.StructuredExtractor instance
StructuredExtractor extractor = new StructuredExtractor();
extractor.RegistrationName = "demo";
extractor.RegistrationKey = "demo";
// Load sample PDF document
extractor.LoadDocumentFromFile(@".\sample3_ocr.pdf");
// Enable Optical Character Recognition (OCR)
// in .Auto mode (SDK automatically checks if needs to use OCR or not)
extractor.OCRMode = OCRMode.TextFromImagesAndVectorsAndRepairedFonts;
// Set the location of "tessdata" folder containing language data files
extractor.OCRLanguageDataFolder = @"c:\Program Files\Bytescout PDF Extractor SDK\Redistributable\net2.00\tessdata\";
// Set OCR language
extractor.OCRLanguage = "eng"; // "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in /tessdata
// Find more language files at https://github.com/tesseract-ocr/tessdata/tree/3.04.00
// Set PDF document rendering resolution
extractor.OCRResolution = 300;
// You can also apply various preprocessing filters
// to improve the recognition on low-quality scans.
// Automatically deskew skewed scans
extractor.OCRImagePreprocessingFilters.AddDeskew();
// Remove vertical or horizontal lines (sometimes helps to avoid OCR engine's page segmentation errors)
extractor.OCRImagePreprocessingFilters.AddVerticalLinesRemover();
extractor.OCRImagePreprocessingFilters.AddHorizontalLinesRemover();
// Repair broken letters
extractor.OCRImagePreprocessingFilters.AddDilate();
// Remove noise
extractor.OCRImagePreprocessingFilters.AddMedian();
// Apply Gamma Correction
extractor.OCRImagePreprocessingFilters.AddGammaCorrection();
// Add Contrast
extractor.OCRImagePreprocessingFilters.AddContrast(20);
// (!) You can use new OCRAnalyser class to find an optimal set of image preprocessing
// filters for your specific document.
// See "OCR Analyser" example.
for (int pageIndex = 0; pageIndex &lt; extractor.GetPageCount(); pageIndex++)
{
Console.WriteLine("Starting extraction from page #" + pageIndex);
Console.WriteLine();
// Fetch all data for rows and columns
extractor.PrepareStructure(pageIndex);
// Write fetched data to console
int rowCount = extractor.GetRowCount(pageIndex);
for (int row = 0; row &lt; rowCount; row++)
{
int columnCount = extractor.GetColumnCount(pageIndex, row);
for (int col = 0; col &lt; columnCount; col++)
{
Console.WriteLine(extractor.GetCellValue(pageIndex, row, col));
}
}
}
// Cleanup
extractor.Dispose();
Console.WriteLine();
Console.WriteLine("Press any key to exit..");
Console.ReadKey();
}
}
Here program is the same as the first example, the only difference is that we’ve enabled OCR parsing and added OCR options like the following.
Set OCR Mode;
Set location for OCR language data files;
Setting OCR language;
Setting PDF document rendering resolution;
Enable the option to automatically deskew skewed scans;
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
There are various automation tools available to automate the application but very few for the desktop application. If you google then you will find a...
LucasArts shut down in 2012 after Disney acquired LucasFilm. It was curtains down for one of the best electronic entertainment franchises. For over three decades,...