Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
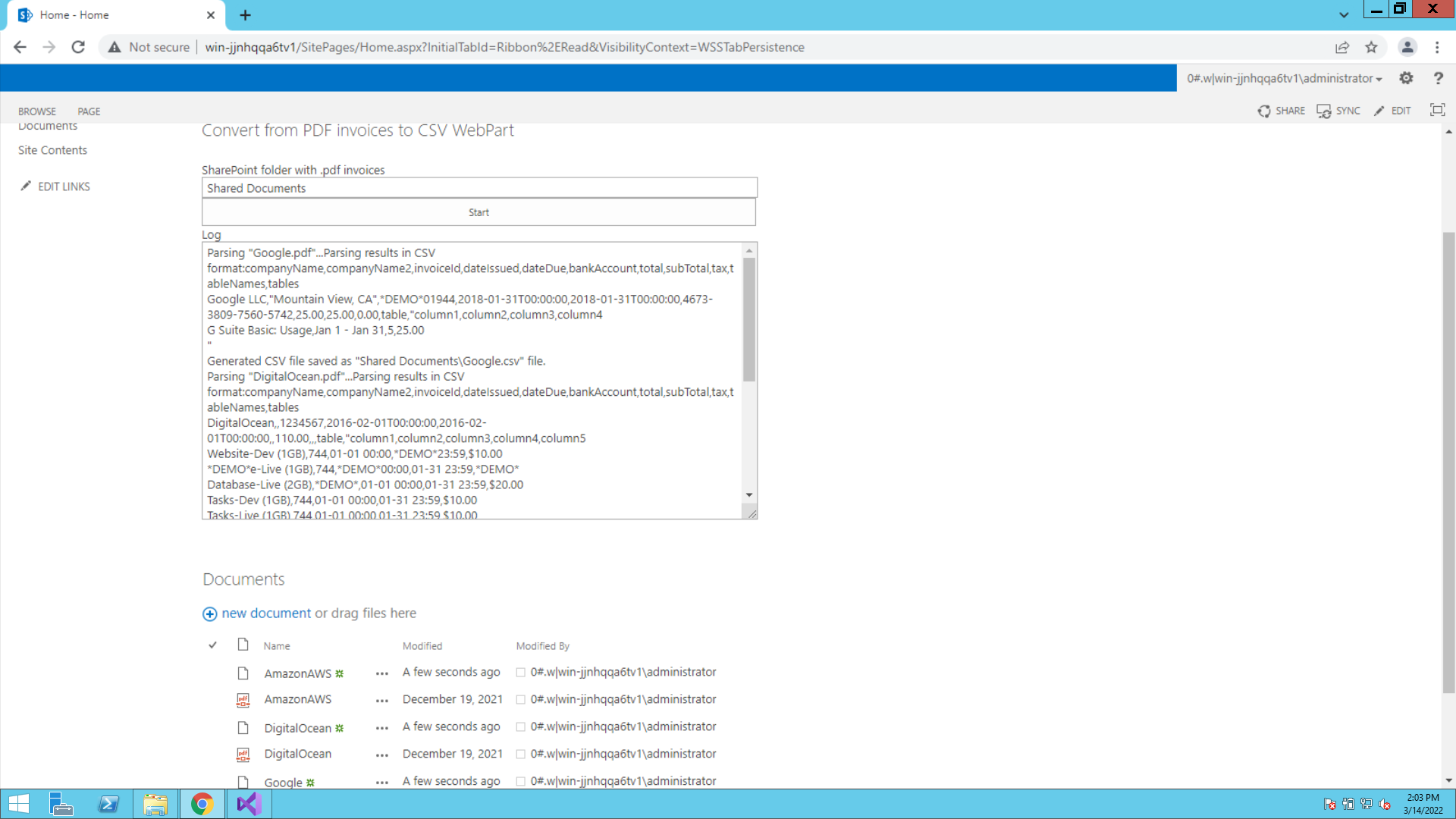
Parsing Invoice using Document Parser SDK and SharePoint
Parsing Invoice using Document Parser SDK and SharePoint
In this article, we’ll review how to parse PDF invoices and get result data in CSV format using ByteScout Document Parser SDK and SharePoint.
Basically, We’ll be following these steps.
Create a SharePoint project in Visual Studio
Give reference to Document Parser SDK
Create WebPart and implement Invoice parsing logic
We won’t be going into macro-level details of how to create a SharePoint extension with Visual Studio. Instead, we’ll be focusing on the code.
The full source code for this sample can be found in this GitHub repository.
Demo
Let’s dive into a demo of the end result. The following screencast demonstrates it all.
Source Code
Now, let’s review the source code. In the next section, we’ll go through the analysis of the source code.
using Microsoft.SharePoint;
using Newtonsoft.Json.Linq;
using System;
using System.Globalization;
using System.IO;
using System.Net;
using System.Web.UI;
using System.Web.UI.WebControls;
using System.Web.UI.WebControls.WebParts;
using ByteScout.DocumentParser;
using System.Text;
namespace ExtractDataWebPart.VisualWebPart1
{
///
/// Extract data from PDF invoices using PDF.co Document
/// Parser (and its default invoice parser template)
/// on a SharePoint folder and then put them back
/// as CSV files on the same SharePoint folder.
///
public partial class VisualWebPart1UserControl : UserControl
{
public SPWeb CurrentWeb { get; set; }
// Destination PDF file name
const string DestinationLibName = "Shared Documents";
protected void Page_Load(object sender, EventArgs e)
{
}
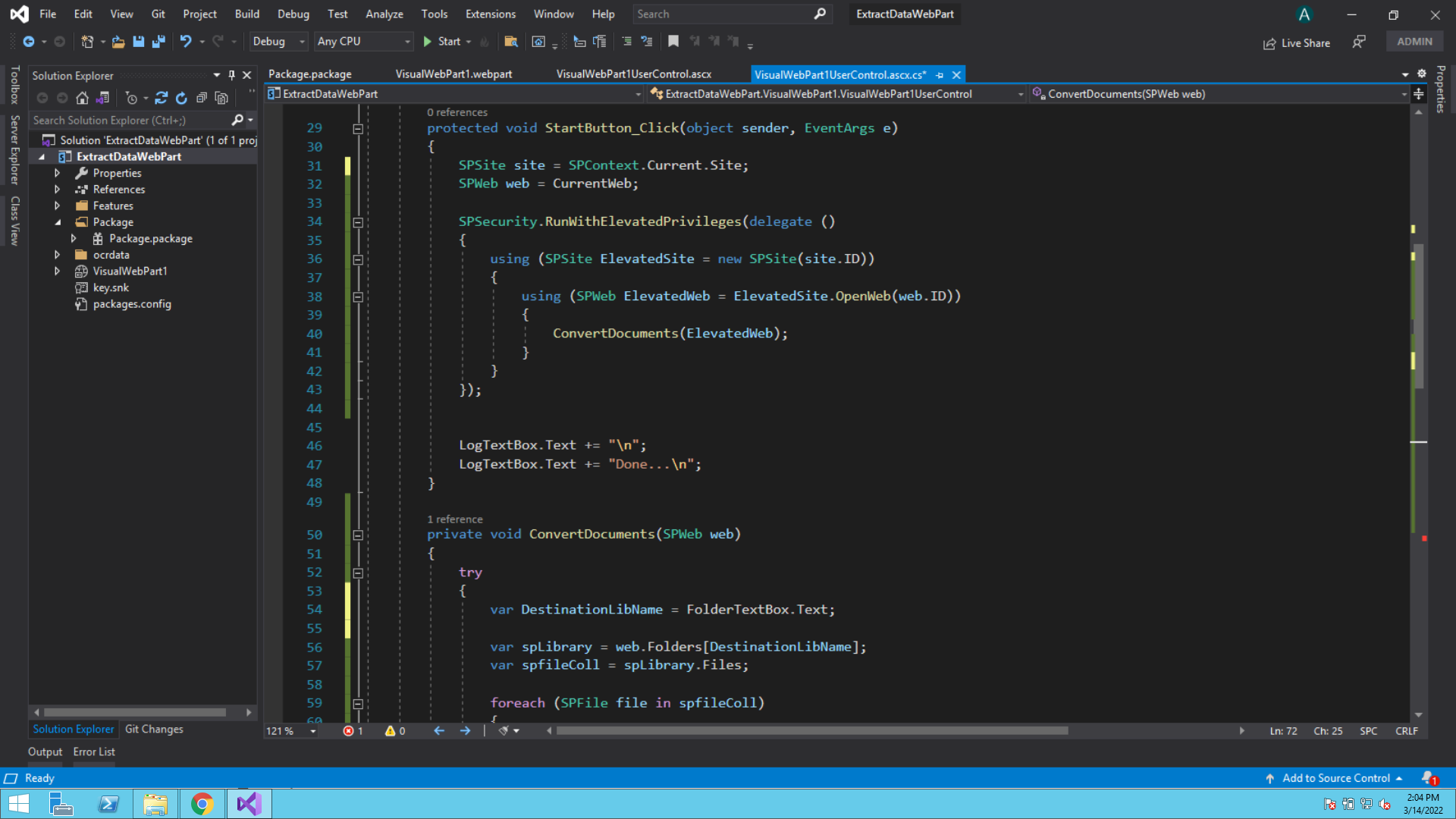
protected void StartButton_Click(object sender, EventArgs e)
{
//string DestinationLibName = FolderTextBox.Text;
SPSite site = SPContext.Current.Site;
SPWeb web = CurrentWeb;
SPSecurity.RunWithElevatedPrivileges(delegate ()
{
using (SPSite ElevatedSite = new SPSite(site.ID))
{
using (SPWeb ElevatedWeb = ElevatedSite.OpenWeb(web.ID))
{
ConvertDocuments(ElevatedWeb);
}
}
});
LogTextBox.Text += "\n";
LogTextBox.Text += "Done...\n";
}
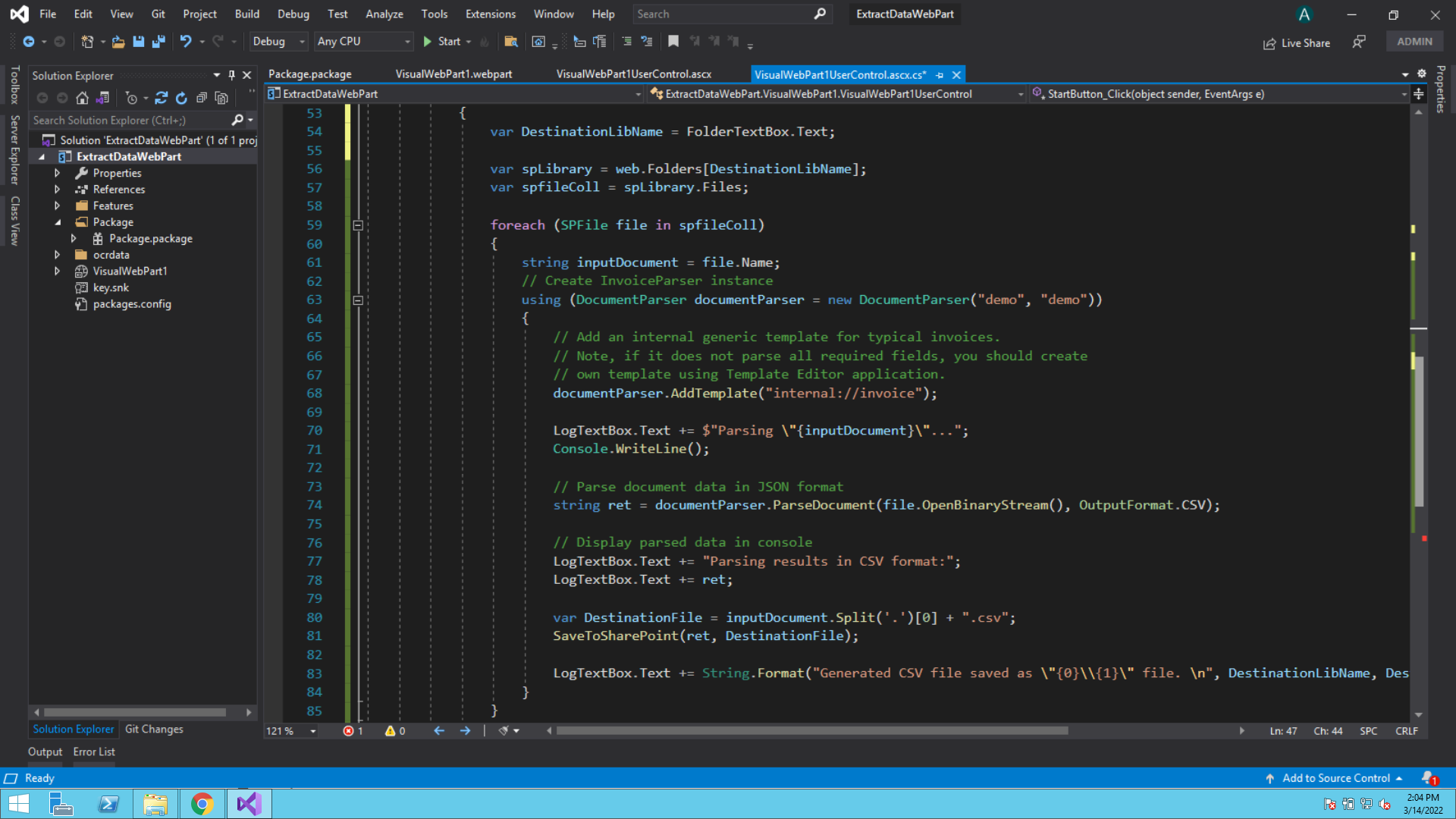
private void ConvertDocuments(SPWeb web)
{
try
{
var spLibrary = web.Folders[DestinationLibName];
var spfileColl = spLibrary.Files;
foreach (SPFile file in spfileColl)
{
string inputDocument = file.Name;
// Create InvoiceParser instance
using (DocumentParser documentParser = new DocumentParser("demo", "demo"))
{
// Add an internal generic template for typical invoices.
// Note, if it does not parse all required fields, you should create
// own template using Template Editor application.
documentParser.AddTemplate("internal://invoice");
LogTextBox.Text += $"Parsing \"{inputDocument}\"...";
Console.WriteLine();
// Parse document data in JSON format
string ret = documentParser.ParseDocument(file.OpenBinaryStream(), OutputFormat.CSV);
// Display parsed data in console
LogTextBox.Text += "Parsing results in CSV format:";
LogTextBox.Text += ret;
var DestinationFile = inputDocument.Split('.')[0] + ".csv";
SaveToSharePoint(ret, DestinationFile);
LogTextBox.Text += String.Format("Generated CSV file saved as \"{0}\\{1}\" file. \n", DestinationLibName, DestinationFile);
}
}
}
catch (Exception ex)
{
LogTextBox.Text += ex.ToString() + " \n";
}
}
private void SaveToSharePoint(string data, string DestinationFile)
{
byte[] bytes = Encoding.ASCII.GetBytes(data);
//Upload file to SharePoint document linrary
//Read create stream
using (MemoryStream stream = new MemoryStream(bytes))
{
//Get handle of library
SPFolder spLibrary = CurrentWeb.Folders[DestinationLibName];
//Replace existing file
var replaceExistingFile = true;
//Upload document to library
SPFile spfile = spLibrary.Files.Add(DestinationFile, stream, replaceExistingFile);
spLibrary.Update();
}
}
}
}
Analysis
We can divide the program into the following logical steps:
With the click of the Start button, start execution
Scan all PDF files in the input folder, and pass them as input
Extract Invoice information in CSV format
Store output CSV to the destination location
The entry point for this execution is the event “StartButton_Click”. As the name suggests, this event gets called on click of the Start button.
In the Start Button click event, basically, we’re creating a Site object and finally executing the “ConvertDocuments” method.
At the start of the program, we’re iterating through all files and processing them individually.
var spLibrary = web.Folders[DestinationLibName];
var spfileColl = spLibrary.Files;
foreach (SPFile file in spfileColl)
{
Then, we’re creating an instance of ByteScout Document Parser SDK. For this sample, we’re using demo keys which give output with a watermark. In production, you should replace it with your License keys which you receive upon the license purchase.
// Create InvoiceParser instance
using (DocumentParser documentParser = new DocumentParser("demo", "demo"))
{
Now that we have the DocumentParser object initialized, it’s time to provide a template used to parse data.
// Add an internal generic template for typical invoices.
// Note, if it does not parse all required fields, you should create
// own template using Template Editor application.
documentParser.AddTemplate("internal://invoice");
In this case, we’re using a generic template for invoice parsing. However, you can create your own template also.
Next, we’re invoking the ParseDocument method, with an argument specifying CSV output type. It’ll return a string containing invoice data in CSV format. Easy!
// Parse document data in CSV format
string ret = documentParser.ParseDocument(file.OpenBinaryStream(), OutputFormat.CSV);
Finally, we’re storing the output in CSV file format at the destination path.
var DestinationFile = inputDocument.Split('.')[0] + ".csv";
SaveToSharePoint(ret, DestinationFile);
That’s all! It’s that easy and convenient to integrate ByteScout Document Parser SDK into SharePoint. This SDK works seamlessly with Scanned Documents and images too!
See you onboard!
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
1. What is Bootstrap? Bootstrap is a highly responsive framework for front-end web development. The implementation of HTML, CSS, and JS is greatly instrumental in...