Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
Extract PDF Data using XMLExtractor in PDF Extractor SDK in C#
Extract PDF Data using XMLExtractor in PDF Extractor SDK in C#
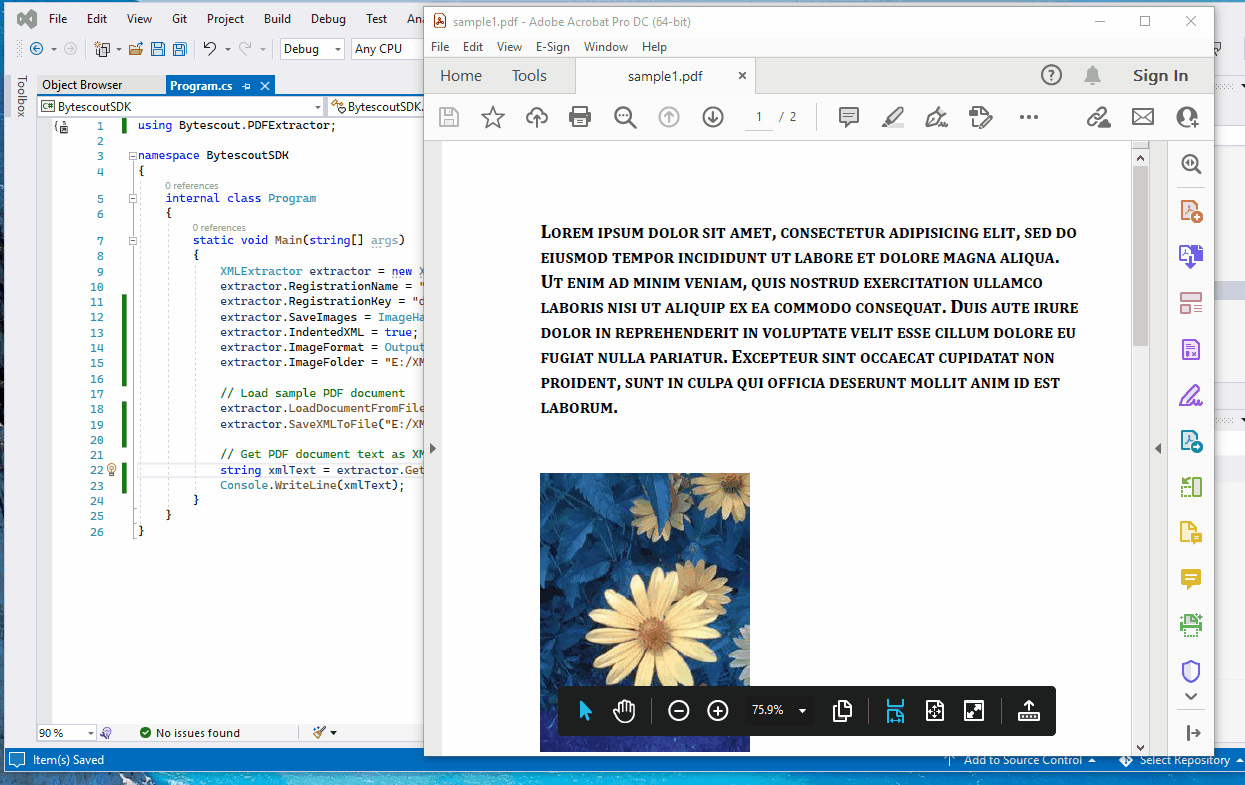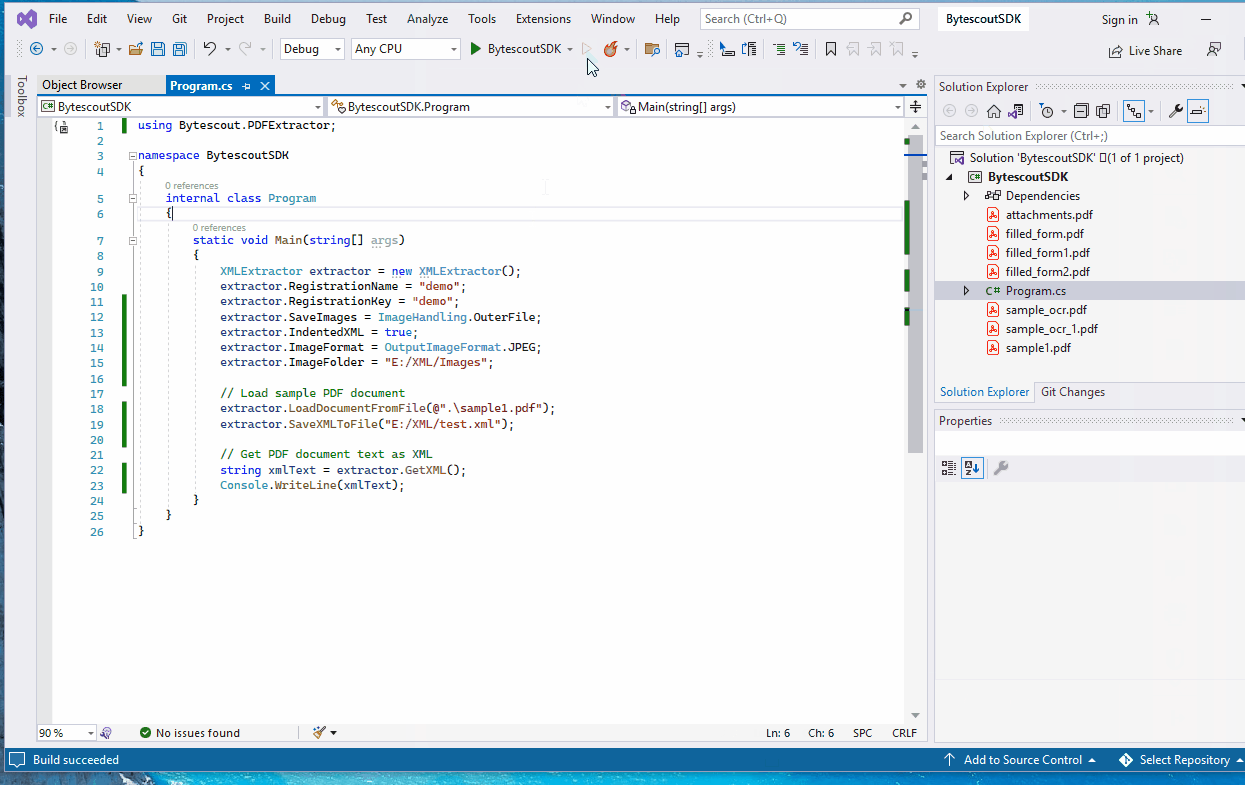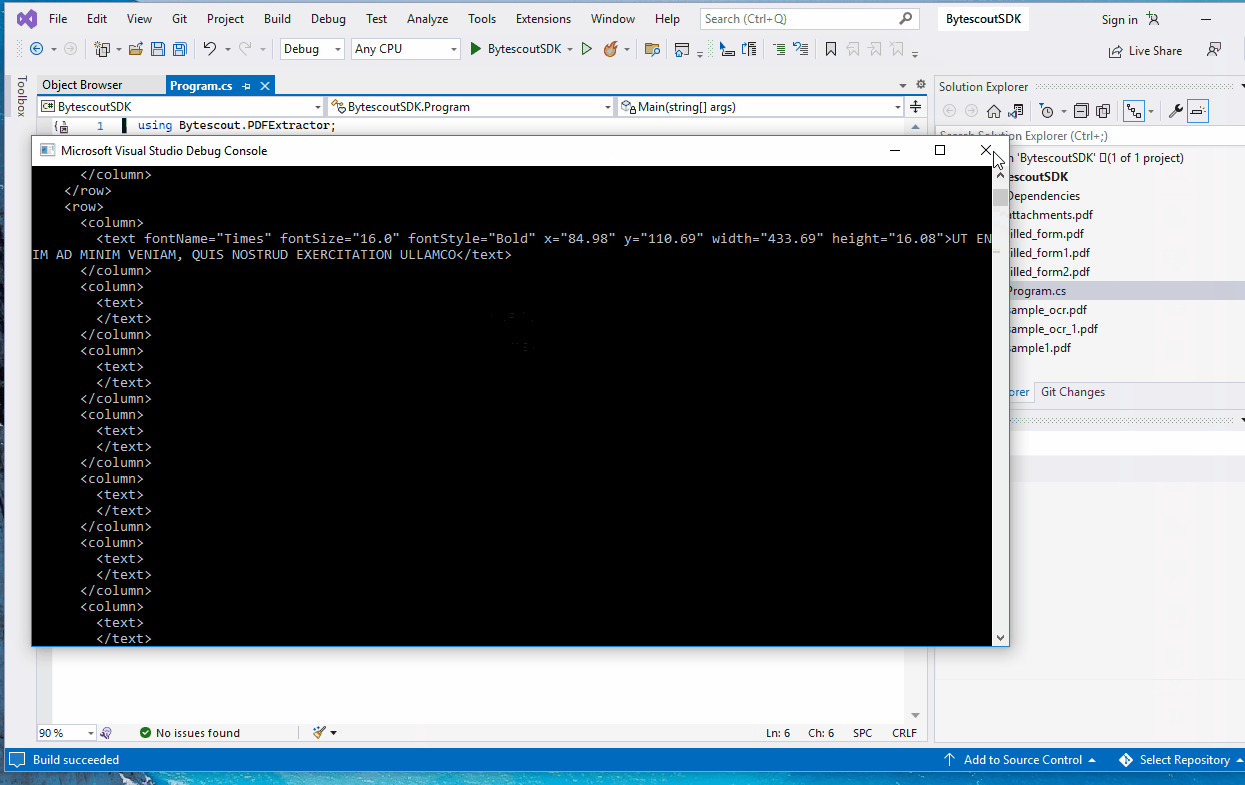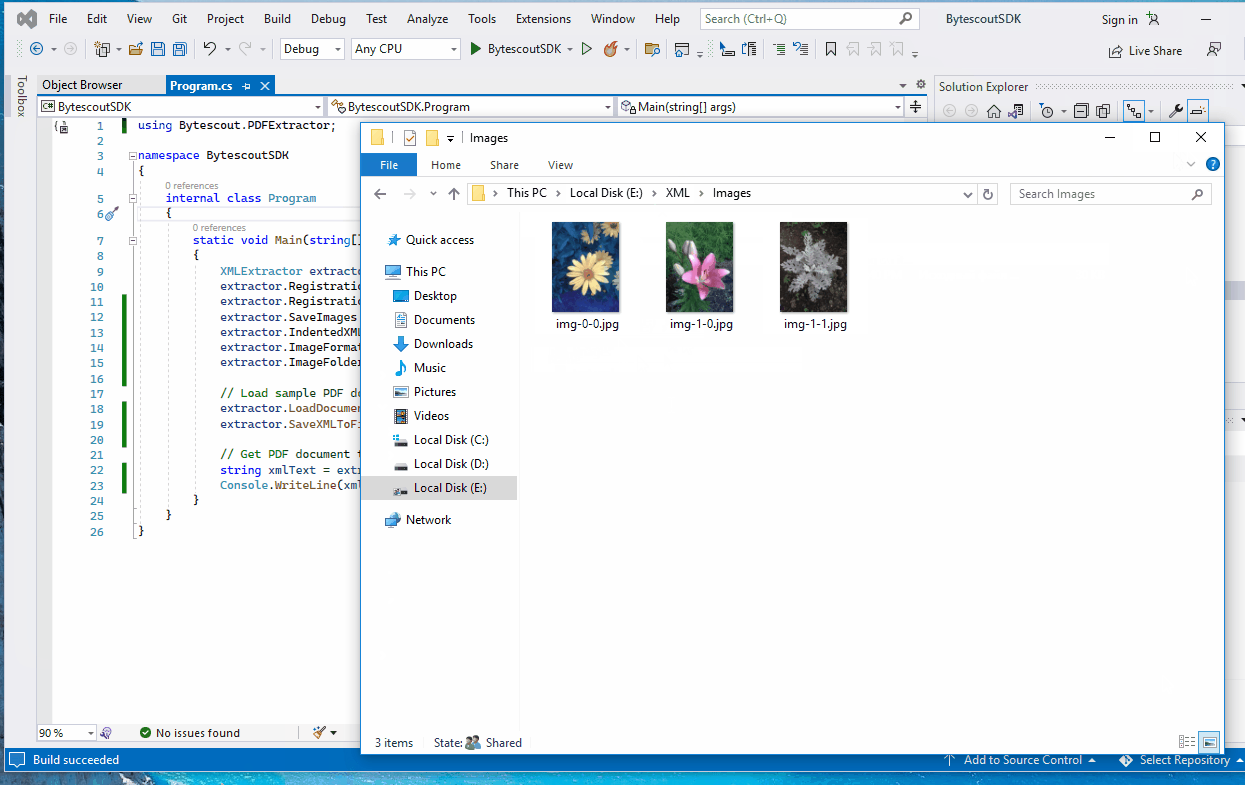
Extractor SDK provides several ways of extracting data from PDF documents and one of them is XMLExtractor class.
Extracting Text and Form Fields
XMLExtractor reads document data and transforms it into XML format.
The resultant XML has a table-like structure and contains the following elements: ‘’document” root element with attributes “pageCount” and “pageCountWithOCRPerformed” which give you the total number of pages in the document and the number of pages on which OCR analysis was performed, respectively.
The child elements of the “document” root are “page” elements the number of which will correspond to the number of pages in the original document. In turn, each “page” is a collection of “row” elements and “row” is a collection of “column” elements:
Actual data is contained in columns and the type of data elements will depend on whether it is a text node or a form field, having element names “text” and “control”, correspondingly.
Attributes in the case of a text node will be “fontName”, “fontSize”, and “x” “y” which show the original location of text on a page, and element content is the text itself. For example:
In the case of a form field, the “control” element in addition to “fontName”, “fontSize”, “x”, “y” attributes will have a “type” attribute that defines the form field type. Possible values of the “type” are listbox, combobox, radiobutton, checkbox, and editbox:
The content of a “control” element is dependent on the form field type. For instance, combobox and listbox will have a set of elements with “value” name, and selected value will have “selected” attribute on it:
Note that a listbox can have multiple selected values and combox just only one item selected.
You can decrease output XML size by setting XMLExtractor.IndentedXML property to “false”. In this case, the output file size will be smaller but less readable since the indentation will be lost.
By default it is set to “true” and the resultant file is better to read, but at the same time it is bigger:
extractor.IndentedXML = true;
XMLExtractor has built-in OCR capabilities which allow you to extract text contained in the embedded raster images. By default OCR is turned off and controlled by XMLExtractor.OCRMode property:
extractor.OCRMode = OCRMode.Auto;
To learn more about available OCR modes in detail please follow this documentation link:
Saving PDF data to an XML file is just as simple as calling XMLExtractor.SaveXMLToFile method:
extractor.SaveXMLToFile("E:/test.xml");
XMLExtractor.SaveXMLToStream will save extracted data in XML format to the specified Stream instance.
Image Handling in XML
XMLExtractor.SaveImages property by default is set to ImageHandling.None, that’s why resultant XML will not have any image embedded, and that is a reasonable default value. Setting it to ImageHandling.Embed will produce XML with included “image” elements with “data” attributes whose values are base64 encoded image content:
Including the images in XML might lead to very big output files and there is ImageHandling.OuterFile setting. It will extract document images and save them to the folder specified by XMLExtractor.ImageFolder property:
There is an option to choose the output image format using XMLExtractor.ImageFormat property. The possible values are PNG, JPEG, GIF, and BMP:
extractor.ImageFormat = OutputImageFormat.JPEG;
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
Data extraction carries a high potential for healthcare applications to allow health policies to regularly utilize data to recognize disorganizations and best methods that enhance...