Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
Continuing our exciting journey through today’s cutting-edge machine learning techniques and SQL methods, we naturally want to develop a practical working knowledge of how to bring all the best predictive technology together in this tutorial on SQL Server Machine Learning Services. Most importantly, we want to build real-world applications. Now it’s more realistic than ever to deploy SQL/Python apps. With this awesome platform we can run Python and R code from T-SQL, and as you may imagine, this creates a great opportunity to combine the most powerful of today’s machine learning algorithms and libraries. SQL tables are especially convenient for managing Big Data for ML apps, and T-SQL extends the power and functionality of ordinary SQL queries. So let’s jump right in because there is a lot to accomplish!
First Steps: Installing your Components
To follow along with our code and example apps here, you will need to install SQL Server first. Go ahead and download SQL Server 2017, and then install Machine Learning Services and enable this feature within a database. A database engine instance is required to run Python and R in this context, and the languages won’t run without the DB engine, so let’s get all required parts and put them together. The “Express” edition of SQL Server is free to download. When the install wizard runs, check all the critical features:
Database Engine Services
Machine Learning Services (In-Database)
R
Python
With SQL Server ML Services you can install Python and R, or either one separately according to your requirements. This means that you can run @script containing code and library functions from both languages within stored SQL procedures!
After your SQL Server installation completes, launch the Server and enable Machine Learning Services to prepare your coding environment for our first example (you will need to restart the server app to get rolling).
Running Python from T-SQL
T-SQL is a proprietary version of SQL which extends programming functionality with local variables and special functions for string and date operations. If you are already familiar with SQL then you will notice the scripting feature extension of T-SQL right away. We will use T-SQL to launch all of our Python example code. But first let’s run a test script to confirm that SQL Server and Python are connected and that everything is configured correctly.
If SQL and Python are connected then you will see “STDOUT message(s) from the external script:” in the message box, along with the calculated result of 40… Did you know that’s the one temperature which is the same in both Celsius and Fahrenheit? In the above code, the important point is the “@script” argument, which tells the interpreter to look for Python code. This is the crux of the matter: we can now run Python and R code snippets from within SQL stored procedures to combine the magic of all three! Remember to follow the usual Python syntax, where spaces designate code blocks instead of semicolons.
Launchpad and Query Window
Next, let’s verify that Launchpad is running, and verify that scripting runtimes are configured to talk to our SQL Server. The interconnectivity of these components is critical to success here. To do this, open a Query Window in SQL Server Management Studio and paste the following recommended test script to the box:
EXEC sp_execute_external_script @language =N'Python',
@script=N'
OutputDataSet = InputDataSet;
',
@input_data_1 =N'SELECT 1 AS HelloWorld'
WITH RESULT SETS (([HelloWorld] int not null));
GO
The sp_execute_external_script statement takes a single input dataset as an argument, and ordinarily, this comes from the result of an SQL query. Many types of input can be supplied, however, and you can even pass a trained ML model as a variable! Stored procedures can return the ever-popular Python Pandas data frame (Pandas is the Python library that provides Excel-like data formats, which are especially convenient for ML tabular data apps). And you can also output scalars and trained models or generate plots. These are some of the common features which we will explore here.
Let’s start by looking at the InputDataSet and OutputDataSet functionality in the above script. What is concealed in the code is the fact that InputDataSet is a Pandas compatible data frame by default, and so the OutputDataSet returns the same data frame object as well. We will leverage this handy feature along the road to mastering the SQL Server Python ML examples here.
Basic Input and Output Formatting
In the code above, the InputDataSet name can be changed with the following line:
@input_data_1_name = N'ThisInputName'
To change the input and output headings, we can follow this example:
execute sp_execute_external_script
@language = N'Python',
@script = N'
ThisOutput = ThisInput
',
@input_data_1_name = N'ThisInput',
@input_data_1 = N'SELECT 1 as Column1',
@output_data_1_name = N'ThisOutput'
WITH RESULT SETS ((Result_ThisValue int))
Python column names are not returned with a Pandas type data.frame, and so it’s important to add headers to your data for clarity.
First Real-World Python ML Model in SQL Server!
Our first serious real-world example has the objective of giving seasoned SQL coders a practical example that demonstrates how to build a machine learning solution with Python code running in the SQL Server. The first step is to add Python code to a stored procedure, and then how to run stored procedures that execute prediction models. Here is a summary of the development process:
Curating and wrangling data
Identifying features appropriate to the model
Training and fine-tuning the model
Coding the model to production
We will focus on the coding and take an existing model that is tried and true for use with our example. You can download the NY City Taxi database from numerous sites online, as this is the dataset of our target model. The easiest way to get this dataset into SQL Server is to use PowerShell script. Actually, the data and code for this example are shared and readily available on Github.
Use PowerShell to Import the Data
To create the necessary db objects and load the NY City Taxi dataset, we will run a script to prepare and set up the environment. The script is also available online as RunSQL_SQL_Walkthrough.ps1 at the mentioned GitHub shared location. Running this script will install SQL Native Client and SQL command-line utilities. The script also creates the necessary database for running this example, as well as a table on the SQL Server instance, and then proceeds to insert the specified Taxi dataset into the SQL table. Open the RunSQL_SQL_Walkthrough.ps1 script in the editor to follow the process. Finally, the example script adds the example SQL functions and stored procedures for building the predictive model.
As you will observe in the standard code sample on Git, the process is straightforward. But please take notice of this excerpt which shows the point at which stored procedures of the ML model are loaded:
Write-Host “run the .sql files to register all functions and stored procedures used in this walkthrough…”
This is a rich predictive model with many functions and stored procedures to experiment with. The focus here is to demo the connection and interplay between the SQL Server environment and the Python initiated by T-SQL. Try running the script yourself to experiment with the outcome.
One stored procedure is fnCalculateDistance.sql which calculates the distance between pickup and drop-off locations. This is a standard SciKitLearn dataset, and there are many predictive models to play with here. For example, the PredictTipSciKitPy.sql actually forecasts the tip based on selected features. There are also several functions for managing and cleaning data.
Data Visualization
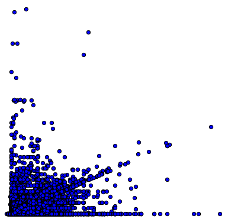
Important to all ML predictive models is the visualization of datasets to the end of identifying feature relevance and interactivity. Visualization may include browsing and plotting datasets in various combinations. We need to become familiar with the NY Taxi Dataset for our example. Take a few moments to look through the column labels and imagine the type of forecasting which might be undertaken, along with the relevant available features. For example, the columns which show known previous tip amounts for trips may be used in a supervised model to predict tips for future trips. Have a look at this SQL procedure to plot data from the Taxi trip dataset for visualization:
[insert plot script? Or link?]
Let’s take a moment to look at several important points about using SQL stored procedures to generate data plots using MatPlotLib. Here is an outline:
@query defines the SQL SELECT query and arguments passed to Python
Matplotlib objects create the histogram and scatter plot
Python graphics object is used to build pandas DataFrame
The plot of Fare (x axis) against Tip (y axis)
The great advantage of using the SQL Server ML Services platform is that it integrates all the familiar functionality of Matplotlib and other familiar Python libraries and brings everything together within the unifying T-SQL context, along with the scripting editor and import functions of PowerShell.
T-SQL to Implement the Python Training Model
Assuming that you have added Python to SQL Server Machine Learning Services sci-kit-learn and revoscalepy packages are now available for building the Python predictive model. Now we can engage in the standard ML practice of splitting the Taxi dataset into training and evaluation datasets. In the following script, we will use a stored procedure called TrainTestSplit to divide the nyctaxi_sample dataset into training and test sets including nyctaxi_sample_training and nyctaxi_sample_testing. This script is also available at the Git location above. Have a look at the execution of this code:
CREATE PROCEDURE [dbo].[TrainTestSplit] (@pct int)
AS
DROP TABLE IF EXISTS dbo.nyctaxi_sample_training
SELECT * into nyctaxi_sample_training FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) < @pct
DROP TABLE IF EXISTS dbo.nyctaxi_sample_testing
SELECT * into nyctaxi_sample_testing FROM nyctaxi_sample
WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) > @pct
GO
The “medalion” in this dataset is the taxi driver’s ID, and the hack_license is the taxi vehicle license. We can run this stored procedure with:
EXEC TrainTestSplit 60
GO
And this will divide the dataset into 60% training data and 40% evaluation data for testing the model’s accuracy. Here we get a glimpse of how convenient it is to bring Python libraries, datasets, and some original code into the SQL Server editor and use these resources to execute forecasting on a variety of typical SQL data tables.
Coming to Life: Deploying the Model
Enough academics – how do we actually deploy and use our example Taxi trip predictive model in the real world? More generally, how do we deploy a model to production? Let’s find out now. The advantage in deployment is the integration of Python code with SQL Server. This renders the job straightforward. All we need to do is add new input by calling the stored procedure from an application and of course passing in the new dataset. Let’s look more in detail at this process.
Several stored procedures are supplied with the Git share mentioned previously. One example is the PredictTipSingleModeSciKitPy for predicting the outcome for a single row of input data. In such a scenario, an application might send a single row of trip descriptive data including passenger count and trip distance as input and request a prediction of the tip based on the training data and the regression model.
USE [TaxiNYC_Sample]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[SerializePlots]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @query nvarchar(max) =
N'SELECT cast(tipped as int) as tipped, tip_amount, fare_amount FROM [dbo].[nyctaxi_sample]'
EXECUTE sp_execute_external_script
@language = N'Python',
@script = N'
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
import pandas as pd
import pickle
fig_handle = plt.figure()
plt.hist(InputDataSet.tipped)
plt.xlabel("Tipped")
plt.ylabel("Counts")
plt.title("Histogram, Tipped")
plot0 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns=["plot"])
plt.clf()
plt.hist(InputDataSet.tip_amount)
plt.xlabel("Tip amount ($)")
plt.ylabel("Counts")
plt.title("Histogram, Tip amount")
plot1 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns=["plot"])
plt.clf()
plt.hist(InputDataSet.fare_amount)
plt.xlabel("Fare amount ($)")
plt.ylabel("Counts")
plt.title("Histogram, Fare amount")
plot2 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns=["plot"])
plt.clf()
plt.scatter( InputDataSet.fare_amount, InputDataSet.tip_amount)
plt.xlabel("Fare Amount ($)")
plt.ylabel("Tip Amount ($)")
plt.title("Tip amount by Fare amount")
plot3 = pd.DataFrame(data =[pickle.dumps(fig_handle)], columns=["plot"])
plt.clf()
OutputDataSet = plot0.append(plot1, ignore_index=True).append(plot2, ignore_index=True).append(plot3, ignore_index=True)
',
WITH RESULT SETS ((plot varbinary(max)))
END
GO
One Big Umbrella!
We have discovered a plethora of benefits for developers and a panoply of new opportunities in pulling Python and SQL into the same platform so that Python code (and also R code) can be included in SQL stored procedures. That is quite an impressive innovation. In this context, the natural partnership of SQL and machine learning can be leveraged. SQL machine learning naturally comes to mind when we imagine Big Data sets now ubiquitous in AWS and other datastores freely available nowadays. Machine learning with SQL in conjunction with SQL Server contains vast resources like low hanging fruit for convenient harvesting and application. Extension to MySQL web applications is the obvious next step in this brilliant evolution in progress today.
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
Some words about .NET Framework are at the previous article .Net Framework is a known Microsoft product which is a programming framework that software applications...