Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
Extract Text from PDF using OCR (Optical Character Recognition) of PDF Extractor SDK in C#
Extract Text from PDF using OCR (Optical Character Recognition) of PDF Extractor SDK in C#
PDF Extractor SDK has powerful OCR capabilities with just as little configuration as possible. It utilizes the latest achievements in the machine learning field and encapsulates all the complexities behind simple API and includes support of multiple languages. Although to extract text from PDF using OCR little configuration is required there are additional options to fine-tune performance and recognition results.
So below are common steps to extract text in supported language from PDF embedded image.
Depending on your needs there are multiple options available, including but not limited to TextFromVectorsOnly and TextFromImagesAndVectorsOnly. So make sure you are using the most appropriate value for you specifically as it can impact recognition time significantly. For example, if your document contains raster graphics only the best option is TextFromImagesOnly, and if it contains both raster and vectors you may need TextFromImagesAndVectorsOnly.
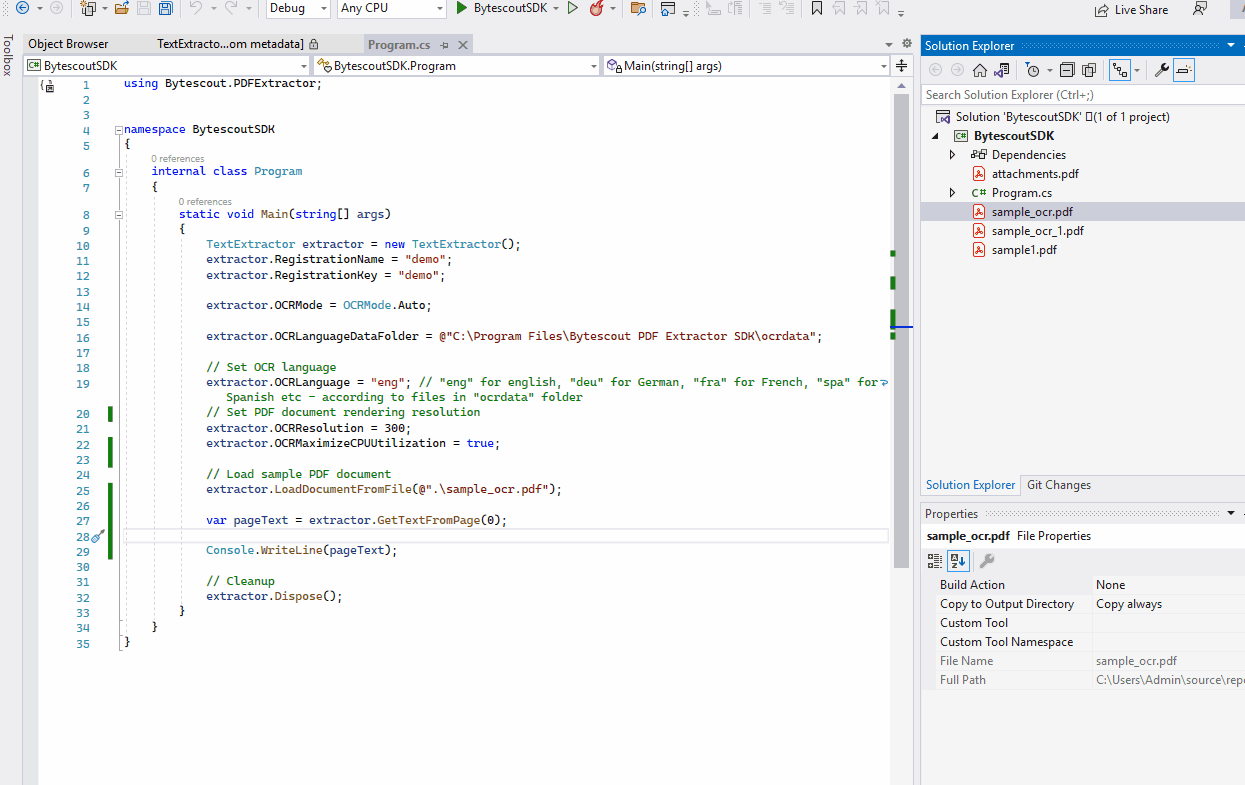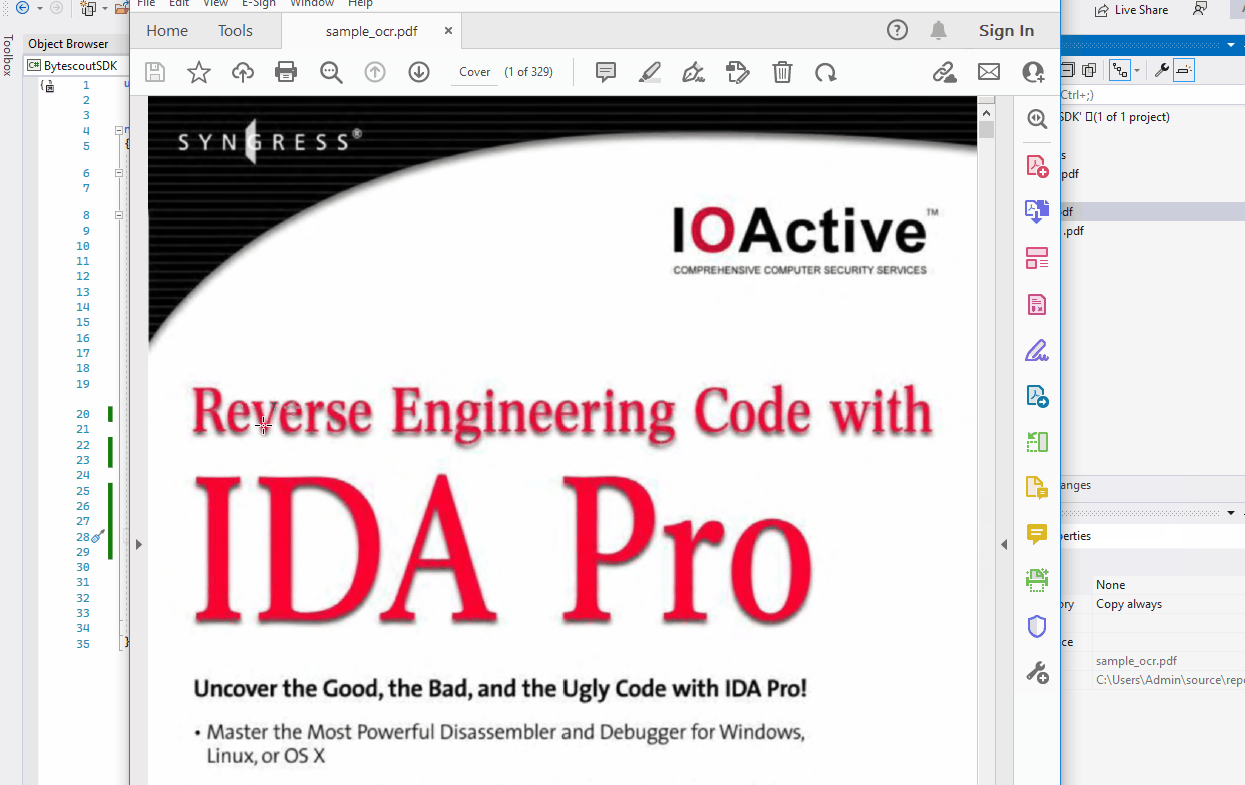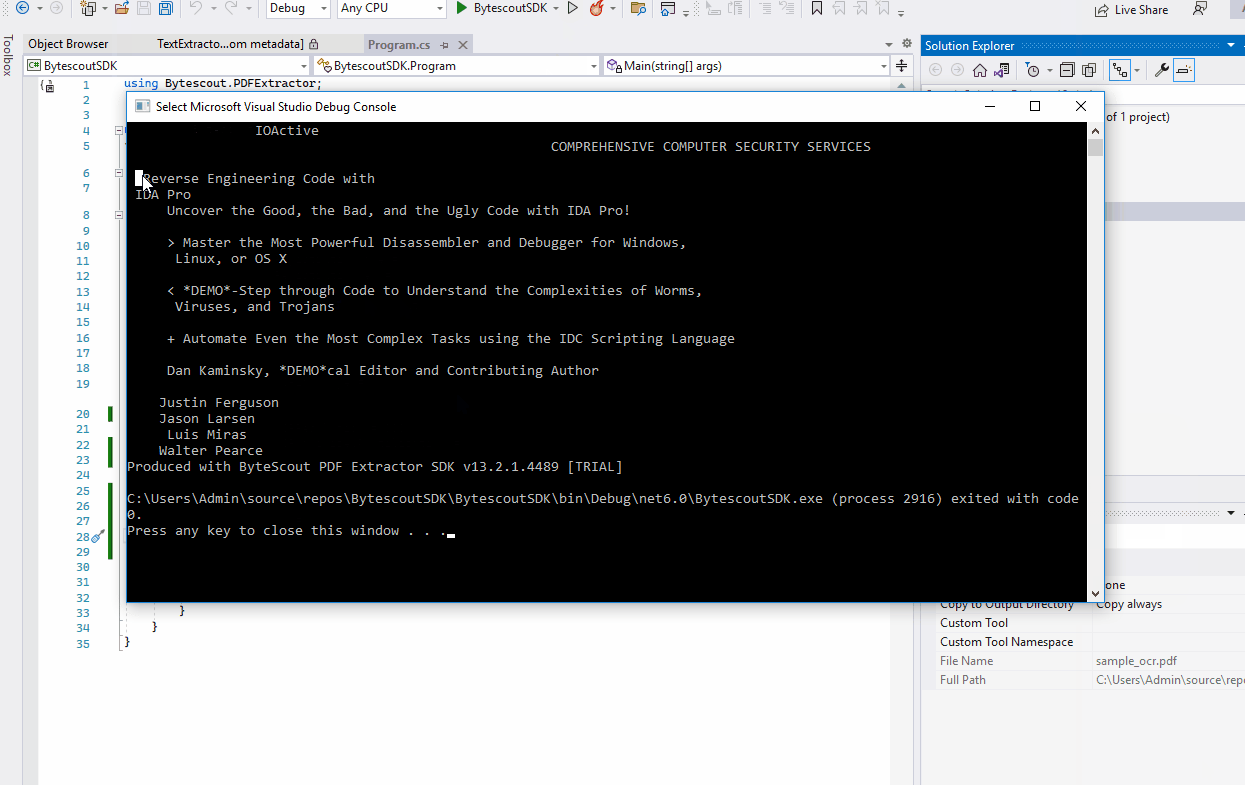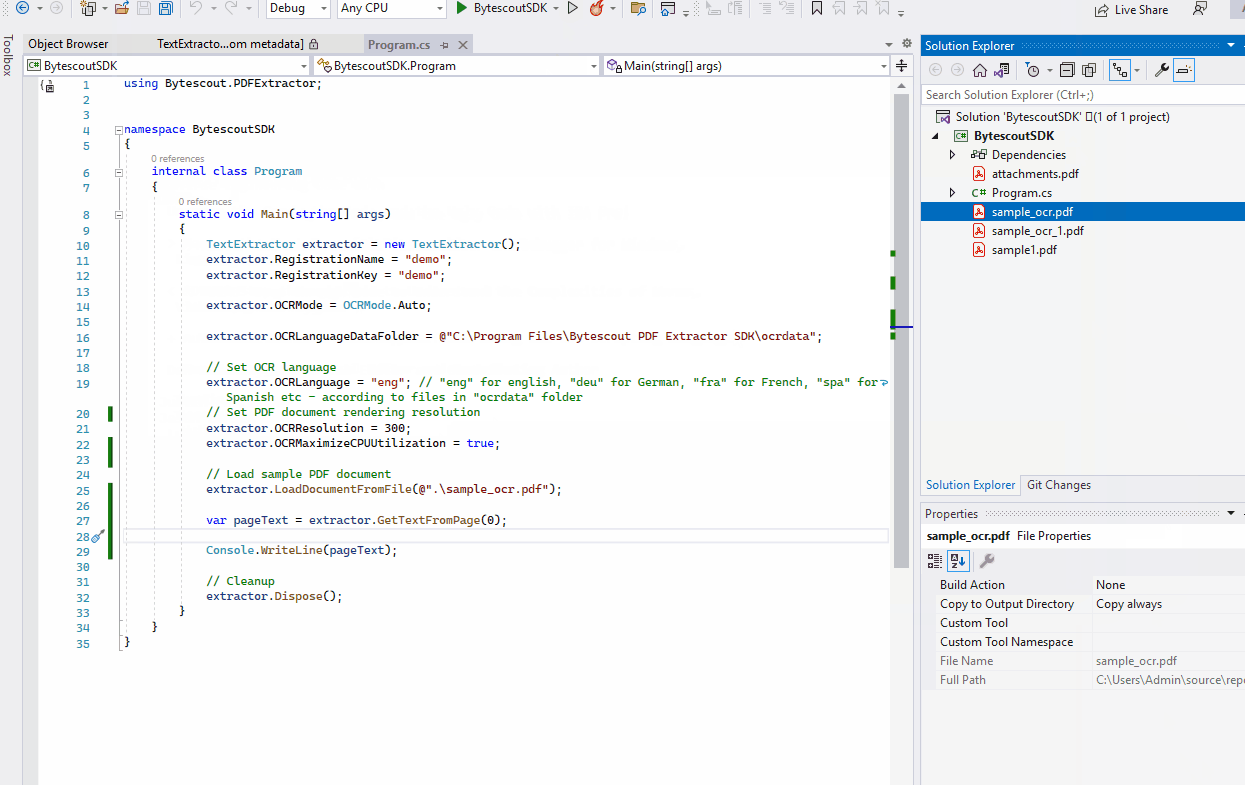
Specify the Data Folder
Specify the data folder which contains language data:
extractor.OCRLanguageDataFolder = @"C:\Program Files\Bytescout PDF Extractor SDK\ocrdata_best";
This is the required property and the string value should point to a valid folder with .traineddata files. The files are included in the standard installation pack and there are several options available. A folder ending with ‘_fast’ can be used if the speed of recognition is very important and you can sacrifice some accuracy in end results. A folder ending with ‘_best’ gives the best results, but performance is a bit slower compared to ‘_fast’ data, so here performance is sacrificed for more accurate results.
Some of the allowed values with predefined data are ‘eng’ for English, ‘deu’ for German, ‘fra’ for French, and ‘spa’ for Spanish, having associated .traineddata file located in the ocrdata folder.
Multiple languages are also supported, so if your PDF contains for example English and German then you have to use “eng+deu” as OCRLanguage value, ‘plus’ sign being a separator there.
Specify OCR Resolution
Specify OCR resolution:
extractor.OCRResolution = 300;
300 dpi is a default resolution and better suited for standard fonts. For smaller font text sizes, like 9 points or smaller, or for lower quality documents higher values of resolution must be used for a good quality end result.
All these settings should be enough to start with the OCR processing of PDF documents. But there are also additional performance tuning settings that you can use to maximize the performance.
Setting OCRMaximizeCPUUtilization to true enables multithreading and utilizes all the CPU capabilities. By default it is disabled, so if loading your CPU to 100% when analyzing is not a problem for you make sure it is enabled:
extractor.OCRMaximizeCPUUtilization = true;
If the document structure is unknown and it might contain for example rotated images there is a boolean property OCRDetectPageRotation. It is set to false by default since setting it to true might affect processing performance, but would also lead to more accurate results in the case of rotated pages present in the document.
OCRImagePreprocessingFilters is a collection of preprocessing filters that are applied before the recognition process to improve embedded image quality. Normally it is used when the quality of raster images is low. Various processing algorithms can be easily added using public methods of collection, such as contrast fixes, rescaling, and noise reduction.
Although adding filters directly to OCRImagePreprocessingFilters collection is the most powerful way of controlling the recognition process, it can require prior knowledge of PDF to be processed, since for example, mistakenly increasing image contrast may hurt quality unintentionally instead of improving it. In such situations where the internal quality of a document is not known and accuracy of recognition is of the highest priority, Extractor SDK offers OCRAnalyzer class. You simply call its AnalyzeByOCRConfidence public method with a specified page number and it will return an object containing a set of recommended filters for that page which can be applied on the specific extractor instance and all the recommended filters will be added to the extractor automatically:
var analysisResults = analyzer.AnalyzeByOCRConfidence(0);
analyzer.ApplyResults(analysisResults, extractor);
Step 4: Load the Target Document
Having set all the initialization values you just need to load the target document and get the result:
Getting the result can be done in several ways, just select the most appropriate for your specific needs.
Extracting all the text from the document:
var text = extractor.GetText();
Extracting the text from the specified page range (by zero-based indexes):
var pageRangeText = extractor.GetText(1, 2);
Extracting the text from the specific page (by zero-based index):
var pageText = extractor.GetTextFromPage(0);
You can also save the text data directly either to a file, specifying the file name, or to a stream using SaveTextToFile and SaveTextToStream methods and their overloads.
Finally, please do not forget and call Dispose on the extractor instance to clean up the used resources:
extractor.Dispose();
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.