Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
Extract Embedded Images and Attachments using PDF Extractor SDK in C#
Extract Embedded Images and Attachments using PDF Extractor SDK in C#
The default installation location of PDF extractor SDK is ‘C:\Program Files\Bytescout PDF Extractor SDK’ where you can find dlls for .net 2.0, 4.0, and core platforms. Make sure to add a project reference to the required platform Bytescout.PDFExtractor.dll when working with SDK.
Along with redistributable, the installation includes SamplesBrowser with code snippets that contain sample projects in different programming languages.
PDF Extractor SDK Initialization
To extract embedded images from a PDF file you have to create a new instance of ImageExtractor class first and initialize it with user registration data:
Next, load the required PDF file into the created instance of the extractor:
extractor.LoadDocumentFromFile(@".\sample1.pdf");
RegistrationName, RegistrationKey, and LoadDocumentFromFile are properties and methods of BaseExtractor abstract class and are common for all extractor classes in SDK. So the document loading and initialization are literally the same for all extractor classes.
How to Iterate Over All Images of PDF Documents and Work with Image Data
Now you can use the extractor API and start working with file images.
To check whether images exist in a document use ImageExtractor.GetFirstImage which will return true if there is at least one image present in the document. It also initializes an enumeration process through existing images at the same time, so you can work with a current image after calling this method using ImageExtractor.GetCurrentImage* or/and ImageExtractor.SaveCurrentImage* methods. ImageExtractor.GetNextImage advances image enumeration to the next image and return false if there are no images anymore to iterate further.
See the common pattern below for enumerating and processing images:
int i = 0;
// Initialize image enumeration
if (extractor.GetFirstImage())
{
do
{
string outputFileName = "image" + i++ + ".png";
// work with the current image as array of bytes or save it with the specified image format
byte[] bytes = extractor.GetCurrentImageAsArrayOfBytes(); …
extractor.SaveCurrentImageToFile(outputFileName, ImageFormat.Png);
} while (extractor.GetNextImage()); // Advance image enumeration
}
ImageExtractor.SaveCurrentImageToFile along with the output file name accepts the additional parameter ImageFormat which allows you to specify the image format to the output image.
To get the exact count of images in the document there is ImageExtractor.GetDocumentImageCount and method to get the count of images on a specific page ImageExtractor.GetPageImageCount(int pageIndex)which you might find handy when working with images.
A set of GetCurrentImageRectangle… method returns image bounding rectangle information which determines the position of the current image on a page within a PDF document.
Another useful method for estimating the image size for any supported image formats is ImageExtractor.GetCurrentImageBytesSize(ImageFormat imageFormat)
ImageExtractor includes ImageExtractor.GetCurrentImageAsVariant which makes possible interoperability with COM/Active-X components and returns an image as Variant object type.
How to Iterate Over Images of a Specific Page
It is also possible to enumerate images of the specific PDF page using zero-based pageIndex. To create such an enumerator use ImageExtractor.GetFirstPageImage(int pageIndex) API. You might need to call ImageExtractor.GetPageCount along with it to be able to iterate over all pages of the document. The following pattern is a typical code you might use to iterate over all images in all document pages:
int pageCount = extractor.GetPageCount();
// Extract images from each page
for (int i = 0; i < pageCount; i++)
{
int j = 0;
// Initialize page images enumeration
if (extractor.GetFirstPageImage(i))
{
do
{
string outputFileName = "page" + i + "image" + j + ".png";
// Save image to file
extractor.SaveCurrentImageToFile(outputFileName, ImageFormat.Png);
j++;
} while (extractor.GetNextImage()); // Advance image enumeration
}
}
Base class BaseExtractor of ImageExtractor implements IDisposable, so do not forget to clean up the resources and call Dispose afterward:
extractor.Dispose();
The existing instance of the extractor can be used with multiple PDF documents, so if you need to load one more PDF into it then ImageExtractor.Reset method must be called just before loading another PDF.
Advanced usage scenarios might involve calling BaseExtractor.SetExtractionArea that expects specific coordinates/rectangles within a document and allows for precise region extraction. To get page coordinates and regions there is BaseExtractor.GetPageRectangle and set of GetPageRect_… methods.
To verify extracted images visually you can start a new process with the default image viewer:
// Open first output file in default associated application
ProcessStartInfo processStartInfo = new ProcessStartInfo("image0.png");
processStartInfo.UseShellExecute = true;
Process.Start(processStartInfo);
Source code of image extraction example can be found by following URLs.
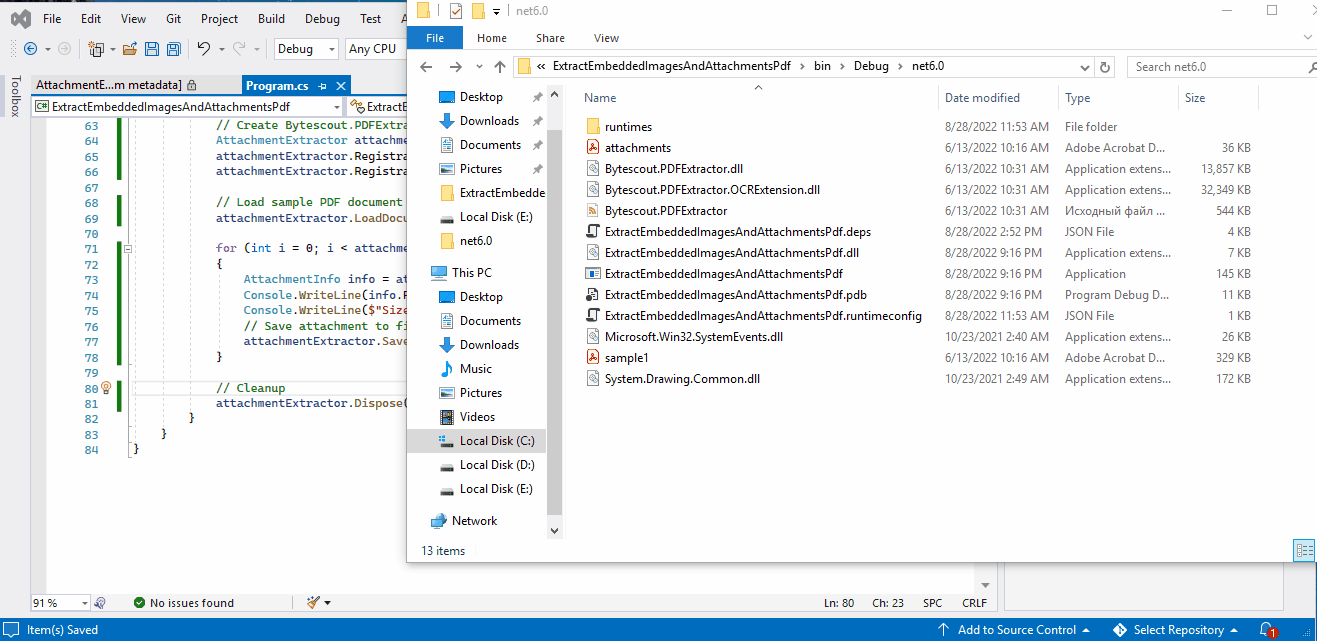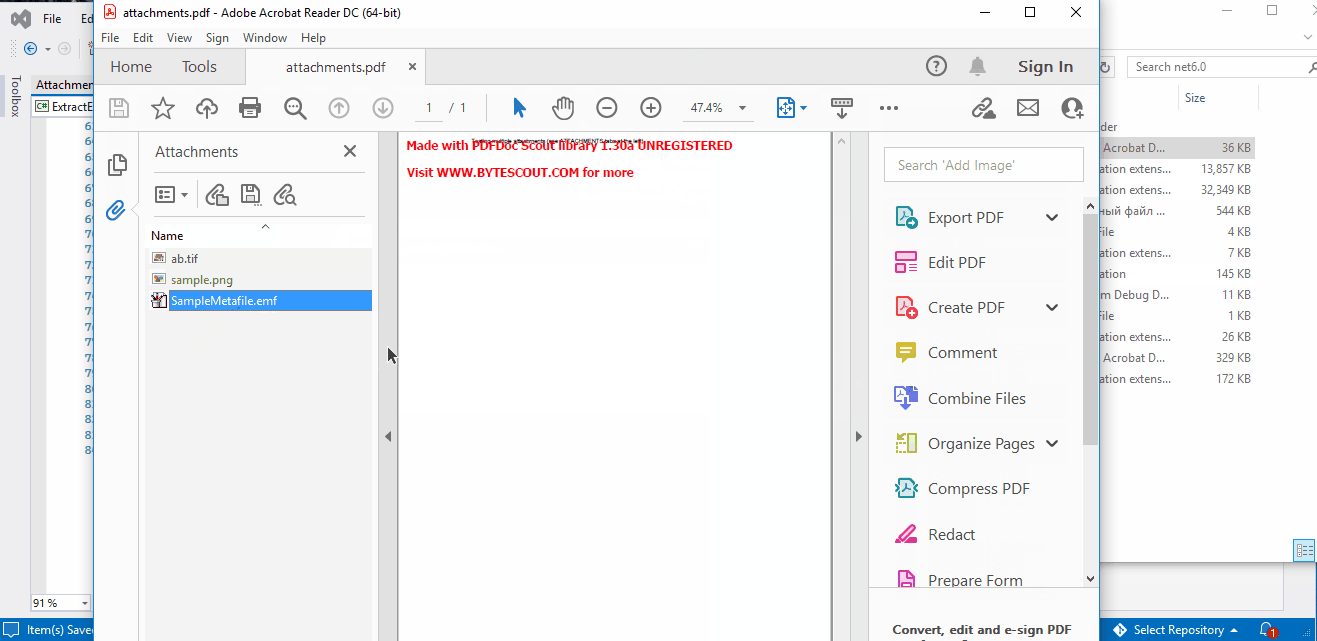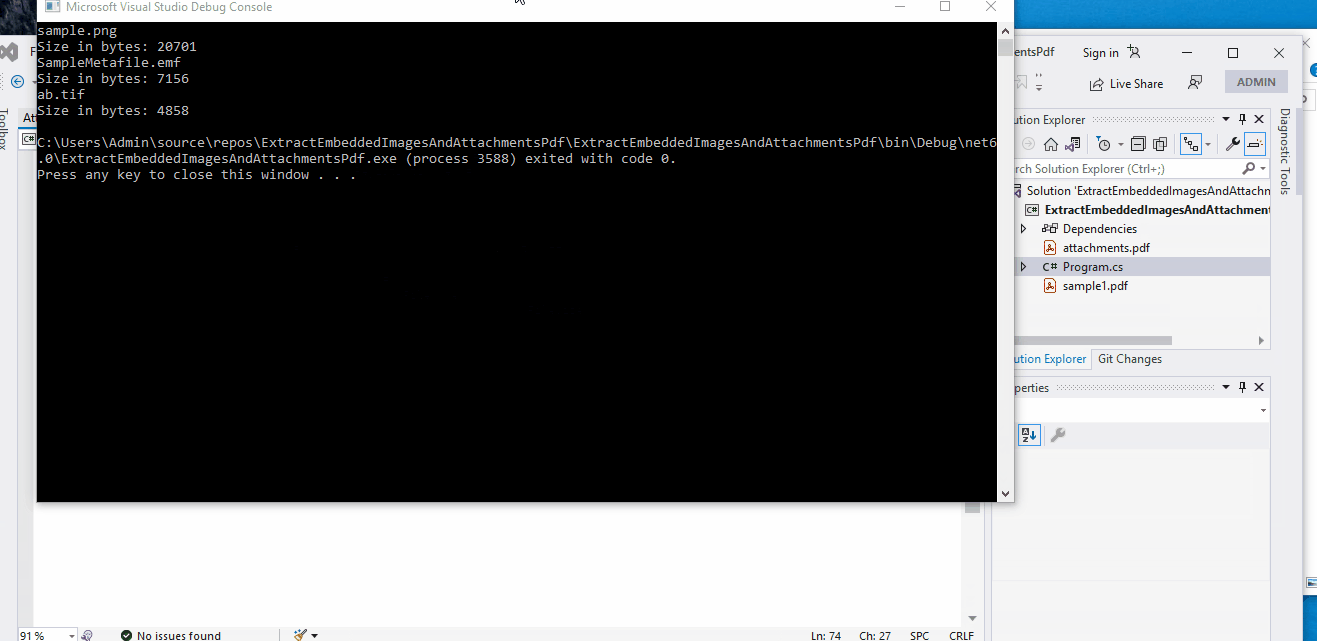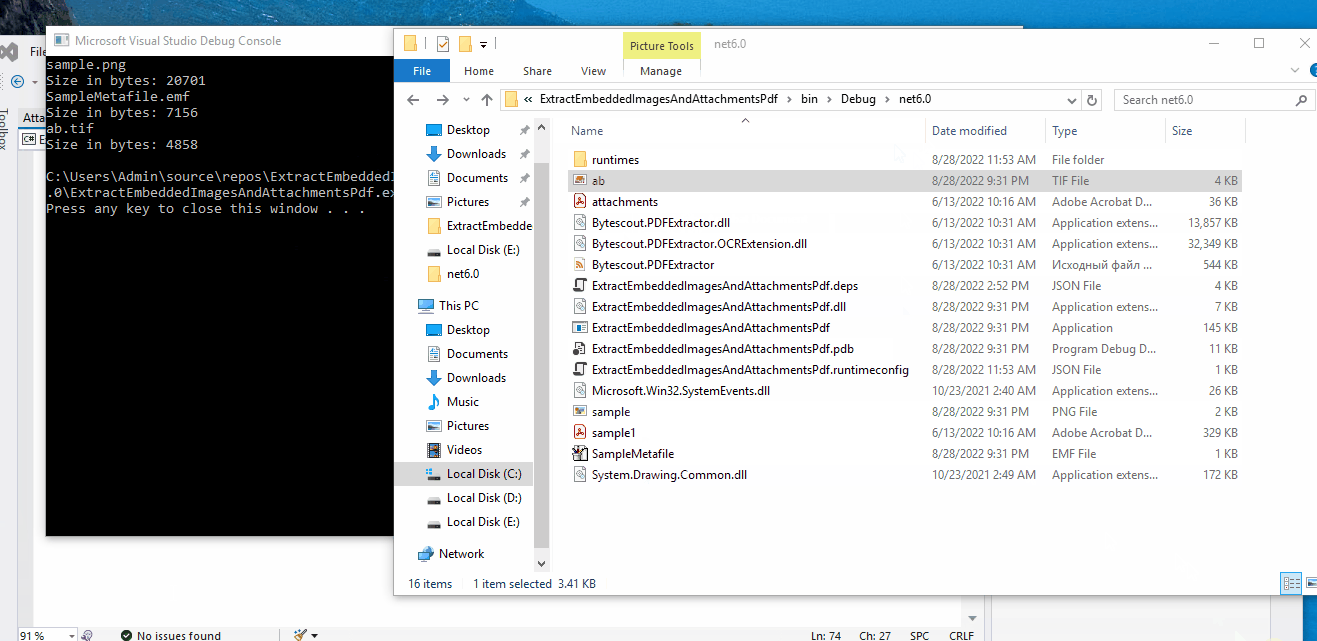
How to Extract PDF Attachments
Bytescout PDF Extractor SDK allows for PDF attachment extraction using AttachmentExtractor class.
AttachmentExtractor initialization is not much different from ImageExtractor class:
// Load sample PDF document containing three attachments
attachmentExtractor.LoadDocumentFromFile(@".\attachments.pdf");
After PDF is loaded it is possible to iterate through all attachments present in the document in a single loop:
for (int i = 0; i < attachmentExtractor.Count; i++)
{
AttachmentInfo info = attachmentExtractor.GetAttachmentInfo(i);
Console.WriteLine(info.FileName);
Console.WriteLine($"Size in bytes: {info.FileSize}");
// Save attachment to file
attachmentExtractor.Save(i, attachmentExtractor.GetFileName(i));
}
AttachmentExtractor API allows saving an attachment to a file, stream, or COM/Active-X compliant variant type. AttachmentInfo class in turn holds all the details about the current attachment and contains a lot of useful properties, some of them are:
Thumbnail - attachment preview in a bitmap format;
FileName - a name of original attachment file
FileSize - attachment file size in bytes
DateCreated - attachment created DateTime instance
DateModified - attachment modified DateTime instance
Again, as with ImageExtractor do not forget to clean up the resources and call Dispose afterward:
attachmentExtractor.Dispose();
The source code for attachment extraction can be found here.
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
Distinguishing Between AI and Machine Learning Clarifying the difference between machine learning and artificial intelligence reveals important distinctions regarding many of the popular buzzwords in...