Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to Extract Document Info and Metadata using PDF Extractor SDK in C#
How to Extract Document Info and Metadata using PDF Extractor SDK in C#
PDF Extractor SDK makes possible not only extraction of actual document data such as text and images but also retrieval of basic and detailed information about the PDF document including its metadata.
To see whether the document is encrypted or not Encrypted property must be used and EncryptionAlgorithm defines an algorithm with which the PDF was encrypted:
To check whether the document contains user-defined properties that are not standard property names there is InfoExtractor.CustomProperies dictionary of user-added properties in the PDF.
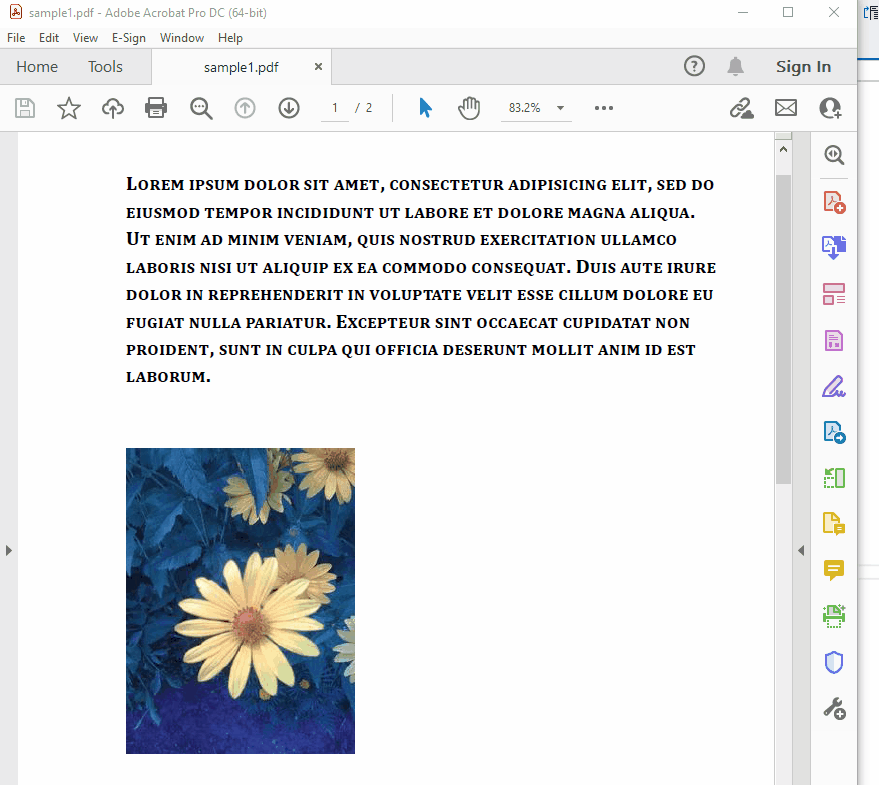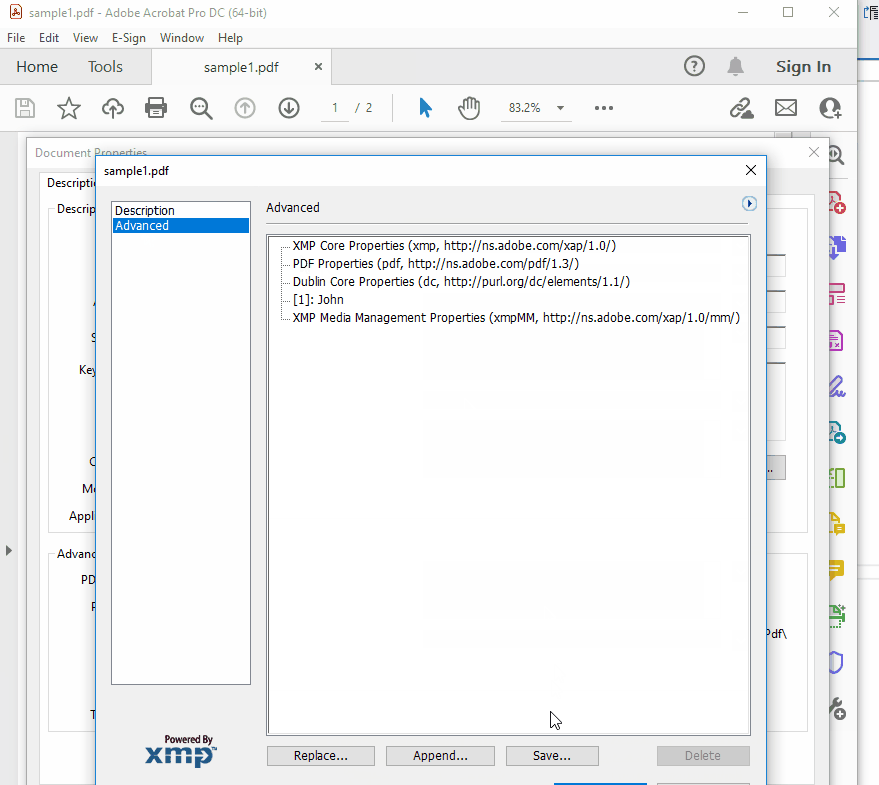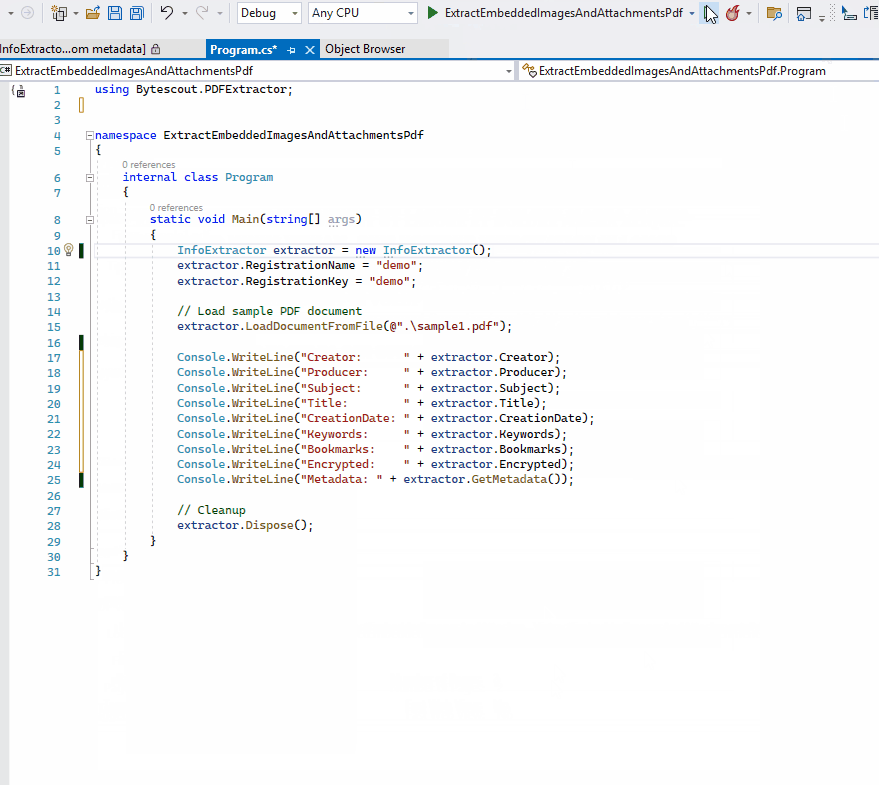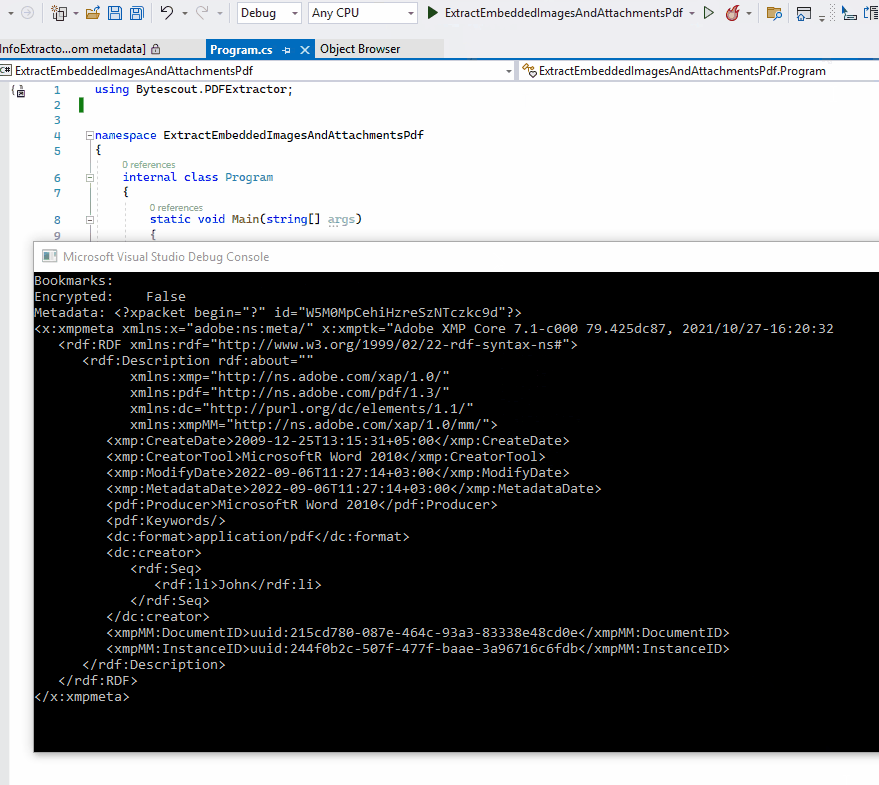
SDK also allows reading metadata streams in XMP format, which is metadata in XML-based format embedded in PDF. InfoExtractor.GetMetadata() method returns a metadata stream available in the document in XMP format.
About the Author
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
Data science is the most important thing in today’s world. It has become a crucial part of many businesses like agriculture, marketing, risk control, fraud...
Data extraction carries a high potential for healthcare applications to allow health policies to regularly utilize data to recognize disorganizations and best methods that enhance...