Our ByteScout SDK products are sunsetting as we focus on expanding new solutions.
Learn More
Important Update
ByteScout SDK Sunsetting Notice
Our ByteScout SDK products are sunsetting as we focus on our new & improved solutions.Thank you for being part of our journey, and we look forward to supporting you in this next chapter!
How to Convert a Scanned PDF into a text PDF Retaining Layouts, Fonts and More with ByteScout PDF Extractor SDK
How to Convert a Scanned PDF into a text PDF Retaining Layouts, Fonts and More with ByteScout PDF Extractor SDK
One of the known problems in data extensive business is to extract data from PDF when PDF is the output of the scanned document. In this article, we’ll see how to extract text from scanned pdf using one of ByteScout PDF SDK. ByteScout is an established player known to provide reliable PDF solutions to developers.
We’ll see through how to convert scanned pdf to text using ByteScout PDF Extractor library. For this program purpose, I have taken one scanned PDF which has scanned images. We’ll process that using the program explained later in this article and check the following steps:
Following is the C# program used to demonstrate how to turn scanned pdf into text using ByteScout library.
using System.Diagnostics;
using Bytescout.PDFExtractor;
// To make OCR work you should add to your project references to Bytescout.PDFExtractor.dll and Bytescout.PDFExtractor.OCRExtension.dll
namespace MakeSearchablePDF
{
class Program
{
static void Main(string[] args)
{
// Create Bytescout.PDFExtractor.SearchablePDFMaker instance
SearchablePDFMaker searchablePDFMaker = new SearchablePDFMaker();
searchablePDFMaker.RegistrationName = "demo";
searchablePDFMaker.RegistrationKey = "demo";
// Load sample PDF document
searchablePDFMaker.LoadDocumentFromFile("sample_ocr.pdf");
// Set the location of "tessdata" folder containing language data files
searchablePDFMaker.OCRLanguageDataFolder = @"c:\Program Files\Bytescout PDF Extractor SDK\Redistributable\net2.00\tessdata\";
// Set OCR language
searchablePDFMaker.OCRLanguage = "eng"; // "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in /tessdata
// Set PDF document rendering resolution
searchablePDFMaker.OCRResolution = 300;
// Save extracted text to file
searchablePDFMaker.MakePDFSearchable("output.pdf");
// Cleanup
searchablePDFMaker.Dispose();
// Open output file in default associated application
ProcessStartInfo processStartInfo = new ProcessStartInfo("output.pdf");
processStartInfo.UseShellExecute = true;
Process.Start(processStartInfo);
}
}
}
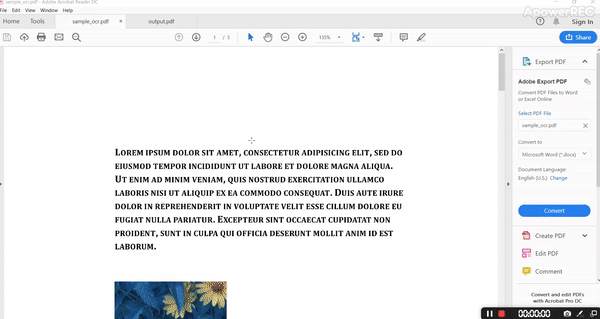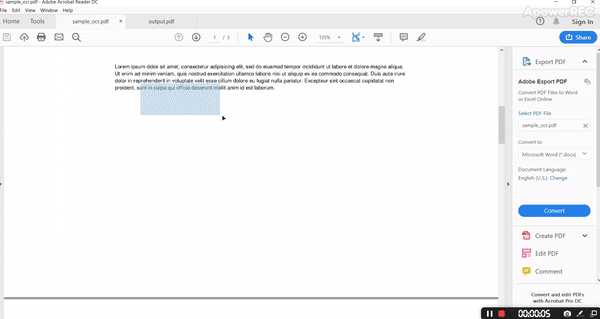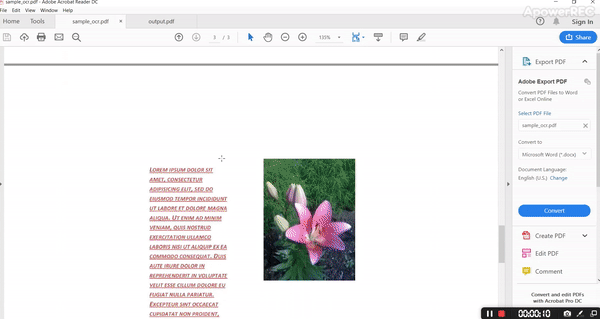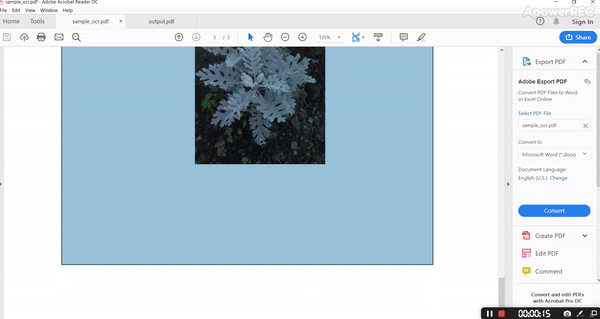
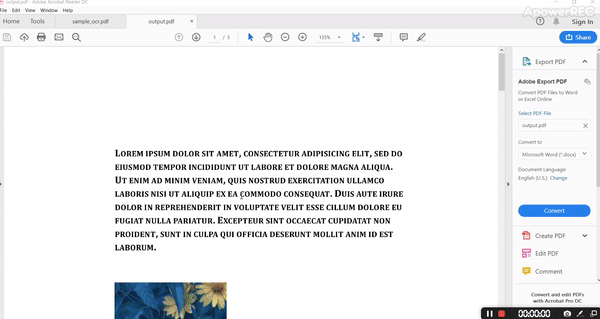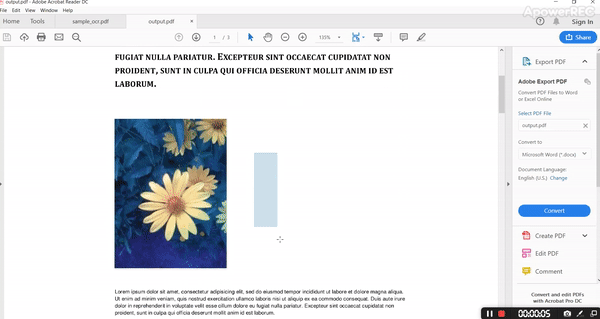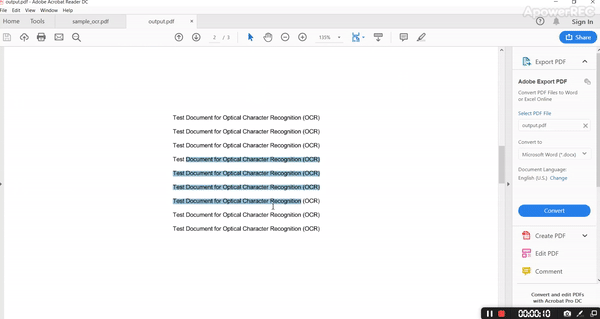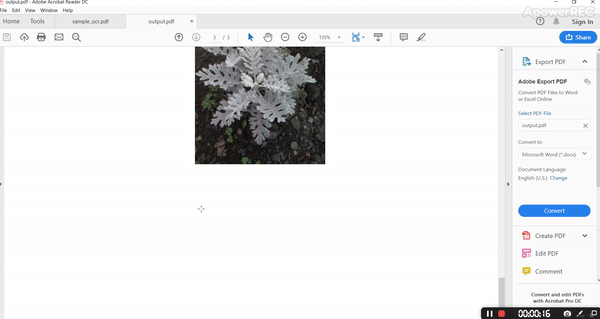
The output PDF is as follows.
By analyzing input and output it’s evident that it’s retaining all the structure with fonts, color, and all style.
ByteScout library provides a solution in many programming languages such as VB, C#, Java, Classic ASP, Delphi, etc. It also provides PDF.co Web APItoo, so that it can simply use with most of the programming language without any installation.
In order to run this program, you need to use the ByteScout PDF Extractor library. One of the easy ways to have this library along with other ByteScout libraries is to install ByteScout SDK at your machine from this link. https://bytescout.com/download/web-installer
Though the code is very simple and self-explanatory, Let’s walk through it to understand how it converts scanned pdf to text pdf.
1. Initialize
Initialize the SearchablePDFMaker instance and load them with registration keys. This needs to be replaced with actual keys. For this demo purpose, I’m using demo keys.
Assign the input file to be processed. Here in this example, we’re using a physical file as an input. We can also use stream object as an input file, in that case, we can use LoadDocumentFromStream method instead.
// Load sample PDF document
searchablePDFMaker.LoadDocumentFromFile("sample_ocr.pdf");
3. Specify OCR Options
Now needs to set OCR options such as a location of the language data folder, language, resolution, etc.
// Set the location of "tessdata" folder containing language data files
searchablePDFMaker.OCRLanguageDataFolder = @"c:\Program Files\Bytescout PDF Extractor SDK\Redistributable\net2.00\tessdata\";
// Set OCR language
searchablePDFMaker.OCRLanguage = "eng"; // "eng" for english, "deu" for German, "fra" for French, "spa" for Spanish etc - according to files in /tessdata
// Set PDF document rendering resolution
searchablePDFMaker.OCRResolution = 300;
OCR works with most human languages. It contains features such as convert scanned pdf to text from rotated images, choosing a specific location for OCR conversation so that it only performs OCR on the selected locations, etc.
Let’s say we need to use different languages used in this example, then the only thing we need to do is to provide appropriate language code and have its language data and provide the correct path for it.
For example, if you need to have support for the Hindi language then need to follow these directions.
// Set OCR language
searchablePDFMaker.OCRLanguage = "hin";
// Need to set Font which supports hindi characters
searchablePDFMaker.LabelingFont = "Arial Unicode MS";
4. Show-Time
With all things set, now we just need to start the conversation and specify the output location.
// Save extracted text to file
searchablePDFMaker.MakePDFSearchable("output.pdf");
Here, we can have multiple options such as saving the output as a physical document or saving it as a stream. We can also control a specific page to be outputted.
ByteScout Team of WritersByteScout has a team of professional writers proficient in different technical topics. We select the best writers to cover interesting and trending topics for our readers. We love developers and we hope our articles help you learn about programming and programmers.
We all use PDF files for one activity or the other. These documents have a significant level of functionality across different fields. In fact, most...